
This post is a feasibility study to see how we can extend the Spring Webflow functionality so it can help us more with Extremely Ajaxified Web Applications with the help of Model Driven Software Development, State Machines and proven JSF library like Primefaces (you can look here to see how the feasiblity study looks like visually).
Feasibility project is available under github.com and I will give here the instruction about how to build and deploy it. I paid special attention that all the technologies used in this project to be Open Source, to be able to give people a chance use these ideas in their projects without being blocked from their project management with the arguments about their costs.
I like to mention, I used capital first letters on the words for the keywords representing important concepts for this blog, I know it is not english grammar conform but I like to emphasize this way, important topics for this blog.
The structure of blog would look like this…
*******SPECIAL NOTE – Spring State Machine, when I wrote this blog, there were no compatible open source State Machine with the requirements of this blog, now I can happily say there is one. I created another blog entry adapting the feasibility study to Spring State Machine. All the motivation reasons why this feasibility study is created, are still explained here. If you want to understand why it is good idea to use State Machines in Web Application, please read this blog entry further. If you want to see implementation details for a Spring State Machine based on an UML Diagram, please read the other blog also.
************
*******SPECIAL NOTE – When I made the previous modifications to the blog to use the Spring State Machine via an UML Model, I was intrigued with the idea to figure it out how difficult would it be to create a Domain Specific Language(DSL) and create Spring State Machine configuration via that way. It seems that is quite feasible also, if you want to know how, please read my blog about the subject XText, Domain Specific Language and Spring State Machine.
************
*******SPECIAL NOTE – It seems the some dependency information of the MWE that I used for MDSD purposes is changed and caused extensive changes on the structure of the feasibility project. Instead of modifying this blog I created a new blog entry which will explain the changes. I will not re-tell the subjects that are not changed in the new blog but only explain the parts effected from the technology change at MWE. So if you want to learn more about the idea expressed here, please continue to read, otherwise the new blog entry is reachable at MWE2 and UML.************
Foreword:
I was a member of Software Development team at 2009 which is fighting with the complexities of an Extremely Ajaxified Web Application. I had a several years of Web Application development experience but I was quite unprepared for the challenges that an Extremely Ajaxified Web Application offered.
Normally J2EE Web Applications are form based applications that the user should navigate to one web form to the other one. This reality stayed like this for really long time in IT world until that business side of IT discovered that men can do really cool things with Ajax functionalities.
Direct consequence is that normally the functionality that we can integrate to twenty web forms, was presented inside of the one web form. The amount of complexity such a decision can bring to a project was a complete surprise to me and to other members of our team.
When the old means of solving these problems were not enough, we have to find new innovative ways like State Machines, UML, Spring Web Flow, Primefaces, Comet Technologies, Asynchronous Processing and learn their limits, specially the limits about Spring Web Flow which you can read here. Primefaces and Ajax integrates also quite seamlessly, if you look to ‘xhtml’ files in github you will find nice examples about how to use Primefaces components in Ajax environment.
I will try to explain in this article the challenges and solutions we found it, appropriate to solve the problem at hand. I started working on this article around 2010 only able to work on off hours and dealing also with a family life 🙂 it took a while to bring at a publishable quality but I still see the same problems exist and no good solutions in sight, so I think the points that I will discuss here are still valid.
Problems:
I have here a sample project that represents the problems we encountered in real world and my proposed solutions for them.
As I previously gave some hints, our problems started when the business side start loading too much responsibility to the single web form in our application. Our team was built from fairly experienced group of developers but we were all quite new to the Ajax world. Naturally we gone for proven solutions and thought MVC of the JSF will be enough as a solution for our problems.
We have to use JBoss and naturally we choose the technology stack of the JBoss with Richfaces.
At the beginning everything was ok, but in short time we are starting reaching controller classes with the sizes 5000 lines of code because of the excessive responsibilities that the views should have.
To make the things spicier, we should have an asynchronous working model. The backend systems that were our partners systems were not able to reach the performance levels required from a modern web applications. We have to send the requests to partners systems but we should not wait for the responses directly. Otherwise these requests will block the front end clients and leave the impression that we have an unresponsive system. So answers from partner systems will be delivered with the Ajax (Comet working model).
As a general rule of tumb, if your system architecture looks like our below, I strongly urges to consider our solution here.
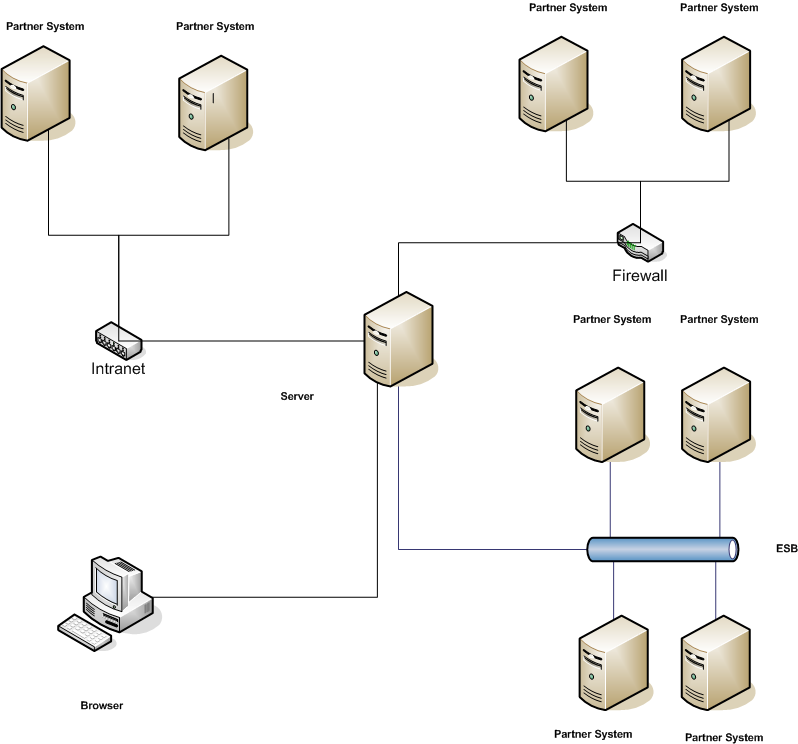
picture 1
As the business side requiring that much information on the forms, a view can practically have 10 areas that we have to display the results. Depending what is contained in the results, these areas may contain another up to 10 elements that we have to turn on or off. So in total, we had up to 100 components that we have to control with Ajax requests.
For you out there that are familiar with JSF, the way control this behavior in JSF to write 100 render methods which will decide that an element should be rendered or not. This was really cumbersome mainly because the logic that will decide what will be displayed or not, was data and user right dependent.
It would at the end look something else.
if(eventA) {
return true;
} else if(eventB) {
return false;
} else if(event C) {
return true;
}
.
..
...
etc
snippet 1
if(userRightA) {
if(partnerSystemResponseA) {
do something
} else if(partnerSysresponseB) {
do something
}
} else if(userRightB) {
do something
} else if(userRightC) {
do something
}
snippet 2
Additionally we had more then one system delivering us information and combined with the asynchronous behavior, we have a complexity that gets out of hand really quickly and we started having real problems.
The cause was that every asynchronous data source meant another thread for the application and an additional event to the application which increased the parallelism. So we started having strange effects depending in which order events are coming into our application.
The things that we developed and tested in development environment were not behaving same during testing because the events were coming in totally different order and timing.
It was really difficult to diagnose the problems. We were not able to reproduce the problems in development environment and the render methods reached an extensive complexity. Simple render method should be aware of all business cases of the application to decide that certain GUI element should be shown to the end user or not.
The render methods that attached to the GUI you saw above, distributed logic, global data container was making to difficult for the project to stabilize it via Unit Tests and some cases impossible to do so.
That was the moment to press the panic button and search for alternative solutions (I am considering, may be you are at this stage while you are reading this article).
From this point on we will make a very detailed discussion about our technical path, if you want to experience how we did reached to the proposed solution please read it further. If you are only interested with the end results please go to chapter ‘Tech Demo’.
Detailed Analysis:
First problem was our lack of experience with Ajax. We had a really experienced group of developers about single threaded MVC style web applications but no particular expertise on Ajax applications. We were believers of the proven frameworks so we started our research there.
The logical starting point was MVC model of the JSF which is one backing bean deciding what should happen in the view. That mean if you will one element to show in the View, backing bean will contain a render method to decide business logic allows to display the elements or not.
That model is fine for, lets 5 elements, may be it is it still ok lets say for 6, 7, 10, 20,… elements but where is the limit. It seems the limits must be much smaller then 10 because as I mentioned previously, the business side of the project was fascinated with the possibilities that Ajax world provides and they loaded the view with this functionality that normally at least will belonging to 10 views…
So we ended up having at least 100 elements and extremely large backing beans (controllers) which are approaching to 5000 lines of codes. At this point it was clear something was wrong.
Unfortunately architecture team didn’t get the clues that we have different type of a problem. They try to solve the problem, which they thought was only code cluttering, with a proven recipe, divide and conquer.
They tried to reduce the responsibility of the backing beans by creating smaller pieces and apply indirections to delegate the business logic.
I accept that in a classical single threaded web application, that would be exactly the solution I would try but we didn’t have a classical web application.
So the solution, instead of providing clarity, had caused more chaos because instead of trying to follow what happening in the system in single place, we have to track over several places which are reaching decisions influencing the flow of the application independently.
As you may see the code was looking better but that didn’t bring any improvement to the quality of life of our project.
The problem stayed same, we were getting some effects that we can’t explain in the production. Our only tool was to read production logs to understand what is going wrong, but reading gigabyte big log files was not easy and that several threads that running business logic, writing their log information at the same time was also not helping.
What we needed was a system that is reporting us, when it encounters an use case that we didn’t thought about in our applications. The question was how to bring such discipline to the project.
Even the single threaded applications contains such use cases, the problem gravitated by us, while we had multiple threads that were running the business logic.
To our luck there was such a methodic, called Finite State Machine.
Finite State Machines are mainly used in rich GUI applications and mostly for the games, for these reasons, at the very beginning we didn’t consider those for our web application. Rich GUI applications and games need State Machines because they process several events at the same time from several different sources. It was not clear to us at the beginning that our application will confront the same challenges.
There were some implementation efforts for the State Machine concept for the web applications, mainly from Spring Web Flow. Naturally we choose look to it as our first solution option.
Spring Web Flow was developed to bring a discipline to the form based applications. It should be documented in XML level which actions (event) causing transitions in the system from one state to another one. This will help to identify the number of the use cases and their States.
Unfortunate fact was that the Spring Web Flow was designed before Ajax 1.0 days. The solutions that it presents are mainly for Form Based classical web applications where any user action will produce a complete post back to the web server and Spring Web Flow will only control the navigation to one web form to the other (off course this is an over simplified view of the Spring Flow, it makes a lot for Action processing and Guard Condition evaluation and some Ajax functionality).
So while we have nearly no Form to Form navigation (our complex application running only inside of one Web Form), was the Spring Web Flow was completely useless for us? What was the added value of the Spring Flow? It was clear that we need to extend the functionality of the State Machine it provides to control the functionality located inside of our one huge Web Form but it was able to present us really good groundwork, specially controlling the lifecycle of the web applications.
After discovering this reality, it was clear that we have to improve the capabilities of the State Machine that Spring Flow contains. To do that the first question we have to answer is that how we are going to transfer our world to this new State Machine.
Should we define our Domain Specific Language for our use cases or is there anything there we can use out of the box. Natural answer to this question is off course is to use UML, which some people which are much more clever then us standardized it already.
The problem there, there is no standard State Machine implementation out there that can take that UML input and execute something. So the other alternative that we have is to take a product out there, which has its own specific DSL and use it.
My personal choice, while I am graphical person, was to use the one of many available open source UML tools to define the contents of a State Machine instead of fighting with megabyte big XML files to read which in my opinion in the long run will kill the acceptance of the solution. If you have a long running project people working on the project will change all the time, one person who is expert on the DSL that you created can deal with it but when the next person would be there, he should spend considerable amount of time to learn this DSL. In comparison, in this age of the IT sector nearly every new employee that you will find will have some understanding of the UML.
The problem we have to solve, is to make UML understandable to an existing State Machine Framework or implement the State Machine Framework ourselves.
The existing Java State Machine Frameworks are built from a complete another point of view then the web applications, which make the integration quite complex. Also most the frameworks were implementing the full fledged State Machine spec which was not necessary for our requirements.
And personally I didn’t want to bring another framework into our project which was already too complex.
One more additional argument that prevented that we use an existing framework, none of them has a really good concept covering the Nested State Machines. This is a really important point for the State Machine theory. A very common problem on State Machine design is the State Explosion, which means if you design a small state machine everything is fine and dandy but when the number of the use cases increase and when transitions from every state to another state is possible the thing gets out of control very quickly.
Fortunately there was always a way to control such problem which is called divide and conquer. This can be explained as following, lets say you have a system you have to search a customer. You can design a State Machine which will hold the overview of the all system under control and several other State Machines that would have smaller responsibilities, like a State Machine that is doing the actual search, a State Machine that will control the authentication system and a State Machine that is controlling the error system and nest all of these State Machines under the State Machine controlling the global use case.
With this method, complexity of the every single State Machine stays in their black boxes and they only present the necessary information out of their boundaries, which eliminate the phenomenon called State Explosion.
Considering these facts, it was more practical to develop a small framework which will understand the UML Model of the State Machine as DSL and with only the necessary feature sets of State Machine.
So the way we followed, we choose an Open Source UML Modelling Platform, the TOPCASED application, Eclipse based graphical UML Modelling tool. The biggest plus side for this tool is that using Eclipse standard implementation of XMI to save the models, which proved to be very critical in the next step (There are other commercial UML tools that are saving there model information as XMI, like Borland Together), but the problem there, they were not following the specifications very closely and this was always causing problems with M2T (Eclipse Model to Text Framework) or Open Architectureware which we will use for code creation.
Now we had a standard way to define our State Machine, how can we convert this information to some executable code for our web application. While we are planning to use Spring Webflow to control the lifecycle of our State Machine parallel to the lifecycle of the Web Application, it seems only natural that we define our executable code with Spring Bean Definition Language (Springs own DSL).
To achieve this, we have to use one principal concepts of Model Driven Architecture and use a Model to Text (M2T) framework to translate our model information to Spring Bean Definition Language. Natural choice was again Eclipse hosted M2T Framework (old Open Architecture Ware).
So the plan is to convert every State Machine defined in the UML model to a State Machine Bean, including this State Machine’s Events, States, Transitions, Guards and Actions to beans also (If you don’t have good grasp of these concepts please read the Appendix about State Machine first).
So our State Machine would be programmed as an Abstract State Machine and these Spring Bean Configuration files will show it how to execute the Business Case.
Well some of you might skeptical at the moment by the choice UML. UML and to some level Model Driven Architecture got really negative reputation lately. If you propose your project leader that you have to base your project to UML, you mostly get an eye roll.
When UML was first become popular, it did really brought big overhead to the project but so little return of investment because when you start receiving changes to your project from your initial system design and nobody invested time to update your model, it stopped being a living document and useful tool.
Especially with the popularization of the Agile Methods, project management had just started seeing UML and Model Driven Architect as a burden because it is established during the initialization phase of the project and becomes outdated with every changes that comes to project.
In our case our State Machine UML is going to be a living document, because our all use cases are going to be represented as State Machines and any changes to the use cases would have to be transferred to the UML documents directly. So this way it is guaranteed the model would be always updated and never will be outdated.
One other great advantage of our methodology would be the testablity. With State Machine by design it is possible to built isolated Unit Test independent from GUI layer and test our use case there which I analyze deeply in the following Appendix
Startup Primers:
At this part I will try to explain the necessary technical background to understand the next detailed explanation of the example project. One thing that I want to point out here, in the following pages you will see that there are lots of ground work to do to make these concepts to work but don’t mistaken when you do the ground work you can use %90 of it for other projects, so there is a really big re-usability factor.
First of all, a state machine from an UML Diagram looks like this…

picture 2
As you see, there is a start point and final point for the system, also States and Transition that connects them, so if you like to know the relation to our system it look like this.
Let’s say our system is started and the main responsibility of this system would be a customer search. When the web page is loaded we will be in STATE_A which represents that we are waiting input from the user to start the search.
When the user gives the necessary input, we will receive Event_A and we will be ready to transition STATE_B which would be represent the situation that we found the customer (there can be more then one transition from one state to others, if all triggered via the same event most probably it would contain GUARD condition to decide which one should be chosen, like checking user rights or some quota exceeded or not).
Search will be executed with ACTION of the transition, this is place the business logic should be executed for a chosen transition.
If this is the User, we like to find in our search that would be the final state of our system but let’s say user is not sure the system delivered the correct information and user likes to see more information, then he can trigger the Event_B to see more details and to transition to STATE_C.
If the user now thinks this is not the correct user, he/she can trigger the Event_C to return to the initial search state to start a new search.
As you may see system only reacts to the commands that it knows, if you send Event_C when you are STATE_A, system will complain that we didn’t teach him what to do for this Event and would not able find a transition and complain about it.
This is the biggest weapon we against the chaos caused by extremely Ajaxified (or multi-threaded) applications we have in the IT world at the moment. The ability that the system tells us that something happened that we didn’t teach to it.
In Web 1.0 world, the application will do something what it thinks fits best to the situation without telling anything to the user. That might or might not fit to the use case of the application.
Now I am hearing, you are asking yourself, can we tell from design phase one all the possible use cases for your application, because if you can’t that means your application will stop in production instead of doing its best bet.
Thankfully Final State Machine fitting really good to the iterative development approaches of the modern IT world. You discover, with each new iteration of your application and you will enhance your model with new information until the software goes into production. If something will even slip under the radar, there are some techniques I will cover at later stages of this article which can help solving some bad surprises.
After experiencing these processes, you will discover at some point in time, final amount of States that you application might have (there can unbelievably many but I guarantee you they are finite). Each iteration will place a piece in the puzzle.
Tech Demo:
As a proof of concept of above mentioned topics, I created a prototype project that uses these concepts. This project lies in github.com everybody can download, uses, changes fitting to their needs.
It is a basically a small scale version of our real life project.
The use case starts with a search of a customer, this is a direct search, when we start the search, partner system will directly deliver the response that the customer is found or not (synchronous system).
If a customer found for the search criteria, the user has to authenticate and approve that the user is correct.
If the user is authenticated, it might or might not give right to join his customer information, if the system found a duplicate information about it in the system.
The use case continues with search of orders for this customer. This simulates a long running search and built asynchronously. Partner system will receive the search request, acknowledge to our system that the request is received, start processing and close the connection. When the results are ready it will callback our system and delivers the result.
There are several side scenarios, like the customer is not found, not authenticated, not allowed to join, authentication cancellation during the order search, join cancellation during the order search.
Our state machine will cover and model all these cases.
We have the following projects forming this Tech Demo.
picture 3
If we have to explain the following picture,
–swf_statemachine is the main project containing the pom (Maven project information) for whole project. I have to use flat maven project model while M2T can’t figure out the nested project structure of the maven.
–swf_statemachine_domain is the where our local implementation of statemachine is modelled and its API from the model created.
–swf_statemachine_fornax_extension, Fornax is creator of the some Maven plugins, archetypes and cartridges(out of box the code generation templates for Java, Spring, Hibernate) for M2T. We have to modify some templates for our purposes.
–swf_statemachine_impl is the project responsible for the implementation code for the API created by the swf_statemachine_domain project.
–swf_statemachine_sm_model is the project we model State Machine depending of use cases. From this project contained UML Model, M2T will create the necessary artifacts (Spring configurations, Java classes to run these State Machines.)
–swf_statemachine_sm_model_impl, previous project created some skeleton of the classes for our live state machine (Guard and Actions can be modelled in UML but there can be only filled with business logic in Java layer), this is the project we will code live Java code for the State Machine.
–swf_statemachine_techdemo is the place, all parts of the puzzle are put together. It is the GUI layer which will contain JSF, Business Logic and State Machines.
–swf_ statemachine_techdemo_domain, while we are following Moden Driven Software Development principles, this project create domain objects from the UML Model via M2T, which will be used in swf_statemachine_sm_model_impl and swf_statemachine_techdemo.
Detailed Functionality of the Projects:
swf_statemachine_domain:
The State Machine Framework that is going to be developed from us modeled in this project. You can see the details in the following UML model.
picture 4
This project model for Model Driven Software Development fundamental elemensts of the State Machine Framework (like State Machine, State, Transition, Guard, Action)
which would be developed from us.
It uses Fornax Cartridges for M2T to create Java Code.
The M2T template ‘Root.xpt’ for interpreting UML Model looks like following.
«DEFINE Root FOR uml::Model» «EXPAND Root FOREACH (List[uml::Package])ownedElement» «ENDDEFINE» * Creates all packages */ «DEFINE Root FOR uml::Package» «EXPAND Root FOREACH ownedType.typeSelect(uml::Interface).select(e|e.getAppliedStereotypes().isEmpty)» «EXPAND Root FOREACH ownedType.typeSelect(uml::Class).select(e|e.getAppliedStereotypes().isEmpty)» «EXPAND Root FOREACH nestedPackage» «ENDDEFINE» /** * Creates all interfaces */ «DEFINE Root FOR uml::Interface» «EXPAND org::fornax::cartridges::uml2::javabasic::m2t::Interface::interface» «ENDDEFINE» /** * Creates all classes */ «DEFINE Root FOR uml::Class» «EXPAND org::fornax::cartridges::uml2::javabasic::m2t::Class::class» «ENDDEFINE» «DEFINE Root FOR Object» «ENDDEFINE» «DEFINE Root FOR PackageImport» «ENDDEFINE»
snippet 2a
With this template, with the help of the Fornax Templates ‘«EXPAND org::fornax::cartridges::uml2::javabasic::m2t::Interface::interface»’ and ‘«EXPAND org::fornax::cartridges::uml2::javabasic::m2t::Class::class»’ we are creating the necessary Java Elements.
M2T Workflow for this project looks like following.
<bean id="uml" class="org.eclipse.xtend.typesystem.uml2.UML2MetaModel"/>
<bean id="datatype" class="org.eclipse.xtend.typesystem.uml2.profile.ProfileMetaModel">
<profile value="platform:/resource/swf_statemachine_domain/src/main/resources/model/Datatype.profile.uml"/>
</bean>
<bean id="java" class="org.eclipse.xtend.typesystem.uml2.profile.ProfileMetaModel">
<profile value="platform:/resource/swf_statemachine_domain/src/main/resources/model/Java.profile.uml"/>
</bean>
<component class="org.eclipse.xtend.typesystem.emf.XmiReader">
<modelFile value="model/domain.uml" />
<outputSlot value="model" />
</component>
<component id="generator" class="org.eclipse.xpand2.Generator"
skipOnErrors="true">
<fileEncoding value="ISO-8859-1" />
<!--metaModel idRef="EmfMM" /-->
<metaModel idRef="uml" />
<metaModel idRef="datatype" />
<metaModel idRef="java" />
<expand value="template::Root::Root FOR model" />
<outlet path="src/generated/java" >
<postprocessor class="org.eclipse.xpand2.output.JavaBeautifier" />
</outlet>
</component>
snippet 2b
We define here UML profile, some custom UML Types for our Workflow and the model the worklow should expand and the model elements that it should expand “template::Root::Root FOR model”.
swf_statemachine_impl:
Is the implementation of the State Machine framework(considered in the scope of our demands, it is not full fledged State Machine implementation).
Main magic happens inside of the StateMachineImpl classes handle event method. Considering State Machine concept is there to control event processing that makes sense.
Which looks like the following
private boolean handleEventInternal(Event event) {
boolean eventHandled = false;
if (this.getActualState().getSubMachine() != null) {
AbstractStateMachine subStateMachine = (AbstractStateMachine) this
.getActualState().getSubMachine();
if (subStateMachine != null) {
eventHandled = subStateMachine.dispatch(event);
if (eventHandled == true) {
return true;
}
}
}
for (Transition transition : getActualState().getOutgoingTransitions()) {
if (event.getEventType().equals(transition.getEventType())) {
if (transition.evaluateGuard(event, this)) {
transition.processAction(event, this);
if (this.getActualState().equals(
transition.getTargetState()) == false) {
if (this.getActualState().getExitAction() != null) {
processExitAction(this.getActualState(), event);
}
}
setCurrentState(transition.getTargetState());
if (this.getActualState().equals(
transition.getTargetState()) == false) {
if (transition.getTargetState().getEntryAction() != null) {
processAction(transition.getTargetState()
.getEntryAction(), event);
}
}
return true;
} else {
if (log.isDebugEnabled()) {
log.debug("Guard condition "
+ transition.getGuard().getClass().toString()
+ " for the transition: "
+ transition.getName()
+ " not letting us to execute the transition for State Machine: "
+ this.getName().getStateMachineName() + " !");
}
}
}
}
log.error(getName()
+ ": We are not finding any transtion for this event type in this state! State: "
+ getActualState().getName()
+ " Event Type: "
+ event.getEventType().getEventName()
+ " the event is for the statemachine: "
+ event.getEventType().getStatemachineName()
+ " and we are at the statemachine: "
+ this.getName().getStateMachineName()
+ " or the guard conditions are not letting us to execute the transition!");
return false;
}
snippet 3
A State Machine should process events in first in first out principle.
That means if it receives an event while it is processing one, it can’t process both in parallel. The reason for this when it is processing an event, State Machine is in an undefined state, you will see shortly that to be able to know which transition we will execute next, we must know in which current State we are. If a State is about to change when we got the second event, then we can’t exactly say which Transitions are valid for the second received event.
For this reason, handleEvent method if it is currently processing an event, it will queue any further event it receives until the first one completely processed.
After the state machine decides, it can process an Event, it looks to the current state and search a valid Transition for the event (handleInternalEvent method). To realise that it gets all the Transitions from the current State and start processing it’s guard conditions, if any of Guard Conditions returns a positive response then it will start executing the Action defined ong the Transition.
At this point, I guess I have to give a brief sample about what can be these Guard Conditions. Let’s say, we are at the search form in our application. User must give as an input, a customer name, so we search our database for it. To allow this, the user must have RIGHT_A. So our applications is initially on WAITING_INPUT state, when the user enters the search criteria and click the search button, State Machine will check what is the current State is, in our case this is WAITING_INPUT and then check this State has a transition for this Event or not.
Lets say there is a TRANSITION_A and this Transition has a GUARD_A which is controlling that the actual user that is starting the search has the RIGHT_A if it is, it will allow State Machine to go in Transition and execute TRANSITION_A’s Action which is to start customer search.
It is as simple as that.
Careful eyes will catch a detail at the begining of this method, before start searching possible transition for this Event we always check first that the current State has a Nested Sub State Machine. This is a very important notion that I will explain later on this Appendix which is mainly related to control the State Explosion problem.
One really interesting object on the UML diagram that I want to point out is the Control Object. This is the heart of the state machine, it represent a meaning of state in the eye of our real life application. Do you remember the discussion that I had at the beginning, that our web form is consisted 20 or more JSF elements and every one them can turned on and off depending the state of our application.
This is the place we control this behavior, let’s say we are in state WAITING_FOR_INPUT in this state only thing that we can display is the input fields and submit button.
At this state our control object will look like this
ControlObject
displayUsernameInput = true
displaySubmitButton = true
displaySearchRunningLabel = false
displaySearchResultTable = false
snippet 4
Now we click the submit button and our application switches to the SEARCH_RUNNING state in which control object will look like as follow.
ControlObject
displayUsernameInput = false
displaySubmitButton = false
displaySearchRunningLabel = true
displaySearchResultTable = false
snippet 5
And when the search is complete and we switch to CUSTOMER_FOUND state.
ControlObject
displayUsernameInput = false
displaySubmitButton = false
displaySearchRunningLabel = false
displaySearchResultTable = true
snippet 6
Considering the values on the Control Object can be only changed from the State Machine, it is a really powerful mechanism. We can protocol every time what value the variables have it, if it is changed, why it is changed
Developers that are fighting all the time with global data containers in a multi-threaded environment can appreciate the power of such a mechanism much better.
Another beauty of the solution that you will see from the following .xhtml snippet
<p:outputPanel id="customerSearchAuthentication-empty-panel">
<p:outputPanel id="customerSearchAuthentication-panel" ajaxRendered="true"
layout="block" style="border:1px solid" rendered="#{customerSearchAuthenticationBB.customerSearchAuthenticationPanelRendered}">
<h:form id="customerAuthenticationForm" >
<h:panelGrid columns="1">
<h:outputText value="If you authenticate the customer please click below!" />
<p:selectBooleanCheckbox id="customerSearchAutheticationCheckBox" title="Authenticated" value="#{customerSearchAuthenticationBB.customerAuthenticated}" onchange="customerAuthenticated();" />
<p:remoteCommand name="customerAuthenticated" action="onCustomerAuthenticated" update=":customerSearchAuthentication-empty-panel,:customerSearchJoin-empty-panel,:customerSearchOrderLoading-empty-panel,:customerSearchOrder-empty-panel" />
</h:panelGrid>
</h:form>
</p:outputPanel>
</p:outputPanel>
snippet 7
interesting part is here ‘rendered=”#{customerSearchAuthenticationBB.customerSearchAuthenticationPanelRendered}”‘, is the way .xhtml code tries to access the information dictates it should be rendered or not.
Most of the today’s JSF applications render methods would like the following.
If( A TRUE) THEN THIS ELSE IF (B TRUE) THEN THIS ELSE IF (C TRUE) THEN THIS
snippet 8
And most of the time A, B, C are going to be global variables which will make testing the whole business logic extremely difficult.
But now look here how our Backing Bean looks like for the isCustomerSearchAuthenticationPanelRendered() Method
public boolean isCustomerAuthenticated() {
CustomerSearchAuthenticationCO customerSearchAuthenticationCO =
(CustomerSearchAuthenticationCO) stateMachine.getControlObject();
return customerSearchAuthenticationCO.getCustomerAuthenticated();
}
snippet 9
Yes, you are seeing it correctly, there is no single if statement, the correct value representing that this part of the GUI should be rendered or not, placed into the variable in the Control Object. When an Event is received by the State Machine and correct value placed to Control Object.
So you don’t have to test the single part of the .xhtml and not the single part of the Backing Bean only thing that you have to test is State Machine and whether or not Control Object has the correct values.
swf_statemachine_sm_model:
This is the project that we are modelling our business cases for the UML State Machine.
From this model, M2T will create executable State Machines via Spring and Java.
Following screenshot is showing the State Machine Diagram of our technical showcase.

picture 5
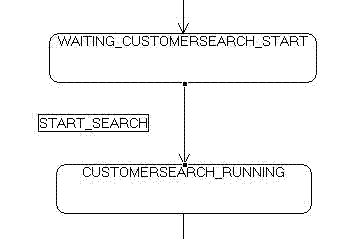
As our use case defines, when the application start, it waits for the user input for the customer search (WAITING_CUSTOMERSEARCH_START State), after the user enters enough information for the customer search, he/she will click the customer search button (START_SEARCH Event) and we will switch to the next state (CUSTOMERSEARCH_RUNNING).
After the partner system, that is searching the customer, reports that the customer is found, it would signal to our State Machine (CUSTOMER_FOUND Event), State Machine will switch to CUSTOMER_FOUND State and wait for the further events that are valid for found customer (CUSTOMER_FOUND State).
In this case, only acceptable event is CUSTOMER_AUTHENTICATED_CLICKED (if by a programming mistake or for an use case that was discovered until now, it receives an another event, State Machine will report this and complain about it. This is the power of the State Machine concept, it provide us an iterative way to complete our Use Case with each discovery).
A Customer Authentication event will take us to the next possible State in our application (CUSTOMER_AUTHENTICATED State), now from this point on, the number of events that we have to respond increases. It is possible that our authentication can be revoked (CUSTOMER_AUTHENTICATION_CLICKED Event) or further continuation of our use cases, Customer Joined (CUSTOMER_JOINED_CLICKED Event) (I just made up this use case, which practically says if the customer previously exists in the system it can be merged with the previous information).
At this state, implicitly an asynchronous search for the orders of the customer is also started. Partner System is contacted and a request is sent. Partner system had acknowledged the request is received then closed the connection. When the results are ready, partner system will call us back with the results.
Now this is a further complication of the AJAX applications, if the user triggers the CUSTOMER_JOINED_CLICKED Event and if the Partner System delivers the results, we have to display the Orders (CUSTOMER_JOINED State) but if the Partner System does not deliver the results and search for the customer order continues, we have to display an order loading screen.
This is decided with the available transition and guard conditions. In our state machine model there are 2 Transitions on CUSTOMER_AUTHENTICATED State which are ready to accept CUSTOMER_JOINED_CLICKED Event. Now State Machine will go over these Transitions and ask to their Guard Conditions, which one of them should execute. Guard Condition checks that an order search is running or not. If it is still running we will display ‘Order Search Still Running Message’ (ORDERS_LOADING State). If the Order Search complete, second Transitions Guard Condition will take us to the display orders screen (CUSTOMER_JOINED State).
At this point this Technology Demo reaches it’s end State (which can be further expanded if it is needed) off course there are some additional use cases to show how useful can a State Machine by reacting to event like what happens when Customer revokes the authentication or un-join the customer. This sort of side scenarios are the real power of the State Machines.
Probably you can look to the main use case and say, I will never develop this with a State Machine what I described above, but bear in my mind that you get the real benefits of a State Machine, if the user will start doing unexpected things like removing the authentication, Partner System start sending unexpected error messages, programming mistakes and so. As it gets complexer and complexer you will need the State Machine more and more.
Model to Code:
Now at this moment we have to clear little bit how we are going to come from this UML model to an executable Java State Machine. You can find a more detailed discussion about M2T in the following Appendix.
M2T (Model To Text) Mechanism will create fundamental structures that knows our use cases and in a further a step we will have fill the content of these structures with live code.
If you check the following directory, you will see that our UML Model stored in XMI format.

picture 6
This is the format that M2T able to interpret and create Java and Spring Code. UML file as a small sample look like following.
For ex, Customer Search State Machine look like following.
<packagedElement xmi:type="uml:StateMachine" xmi:id="_vsIb0H1REeCgupXlFDV_aQ" name="CustomerSearchSM" submachineState="_BWlu8k3XEeOE05lJ4YwKXQ">
<region xmi:id="_vsIb0X1REeCgupXlFDV_aQ" name="Region">
<subvertex xmi:type="uml:Pseudostate" xmi:id="_2m3ZUH1REeCgupXlFDV_aQ" name="start"/>
<subvertex xmi:type="uml:State" xmi:id="_41VcAn1REeCgupXlFDV_aQ" name="WAITING_CUSTOMERSEARCH_START"/>
<subvertex xmi:type="uml:State" xmi:id="_NNY6Qn1SEeCgupXlFDV_aQ" name="CUSTOMERSEARCH_RUNNING"/>
<subvertex xmi:type="uml:State" xmi:id="_gvoDIoEpEeC0au1QwVWf1Q" name="CUSTOMER_FOUND"/>
<subvertex xmi:type="uml:State" xmi:id="_X3DXgobdEeCgzO61Ewoybw" name="CUSTOMER_AUTHENTICATED"/>
<subvertex xmi:type="uml:State" xmi:id="_qRRQ0odxEeCgzO61Ewoybw" name="CUSTOMER_JOINED"/>
<subvertex xmi:type="uml:State" xmi:id="_9kBRUMQhEeCYBJYY66CQSA" name="ORDERS_LOADING"/>
<transition xmi:id="_CqMBRn1SEeCgupXlFDV_aQ" name="InitialTransition" kind="local" source="_2m3ZUH1REeCgupXlFDV_aQ" target="_41VcAn1REeCgupXlFDV_aQ"/>
<transition xmi:id="_WYYDJX1SEeCgupXlFDV_aQ" name="SearchRunningTransition" kind="local" source="_41VcAn1REeCgupXlFDV_aQ" target="_NNY6Qn1SEeCgupXlFDV_aQ">
<trigger xmi:id="_cOjzYH1SEeCgupXlFDV_aQ" name="onStartSearch" event="_kvhH0H1SEeCgupXlFDV_aQ"/>
</transition>
<transition xmi:id="_lJ_8tYEpEeC0au1QwVWf1Q" name="CustomerFoundTransition" source="_NNY6Qn1SEeCgupXlFDV_aQ" target="_gvoDIoEpEeC0au1QwVWf1Q">
<trigger xmi:id="_l_gBUIEpEeC0au1QwVWf1Q" name="onCustomerFound" event="_qTnh4IEpEeC0au1QwVWf1Q"/>
</transition>
<transition xmi:id="_cQF0VYbdEeCgzO61Ewoybw" name="CustomerAuthenticatedTransition" source="_gvoDIoEpEeC0au1QwVWf1Q" target="_X3DXgobdEeCgzO61Ewoybw">
<trigger xmi:id="_dXwnAIbdEeCgzO61Ewoybw" name="onCustomerAuthenticatedClicked" event="_PaRzsIeGEeCgzO61Ewoybw"/>
</transition>
............
</region>
</packagedElement>
snippet 10
These are logical XML elements that are easy for M2T framework to interpret and they are actually human readable also.
Of course, we will need the M2T DSL to be able to create the artifacts we need from these UML model, a small Snippet looks like following (At Appendix, I will give a much clear explanation of how they are working).
These DSL files are located on the following directory.
picture 7
M2T DSL looks like the following
«DEFINE StateMachines(uml::Model model) FOR uml::StateMachine»
«IF this.getAppliedStereotype("swf_statemachine::SwfStateMachine")!= null»
«IF !this.getValue(this.getAppliedStereotype("swf_statemachine::SwfStateMachine"),"submachine")»
<!-- «name.toFirstUpper()» State Machine -->
«LET name AS localName»
«EXPAND StateMachinesCommon(model, this, localName)»
«ENDLET»
«ENDIF»
«ENDIF»
«ENDDEFINE»
snippet 11
Above snippet will create a State Machine in Spring configuration files for each UML State Machine that we have in the model.
With the implementation of the Guard Conditions, Actions and Control Objects, we will implement the functionality to these structures.
For now, when M2T executes against this UML model, for the above mentioned use cases, it will create the following artifacts.
– First, the State Machine definitions will be expressed as Spring Beans (That is the beauty of this solution, we are not inventing another DSL to express these information but using the Spring notations to express them, which is well know for nearly all above average developer).
– Second, an Abstract Java classes representing the control objects for every State Machine that exists in the System.
– Third a Java Enumeration that representing all the State Machines in our model.
– Fourth a Java Enumeration for every States that exists in the model for a State Machine.
– Five a Java Enumeration for every Event that exists in the model for a State Machine.

picture 8
M2T produces 3 XML files containing the bean definitions, each one named with the name of the State Machine which contains the definition of the State Machine, States and Transitions. Another one is defined for the Control Object and one for the Guard Conditions and Actions.
Now you can ask, why 3 files, one is not enough? Actually it is enough but one of the biggest strengths of the State Machine, is the testability of the whole State Machine and Business Logic in a test rig (As you can see in the following Appendix). If we put the definitions of the Control Objects, Guards and Actions into the one single file, we can only make an integration test with real life implementation. Which can be possible for some projects but for the most scenarios out there, unit testing is much more viable, with this structure, we can change the implementation of our Control Objects, Guard and Actions for test ones and test the whole State Machine in a test rig.
Now think the power of this, if it is not clear to you, in how many web applications you can test whole business logic with the all layers of GUIs, DAO, Facades and all sort of technological barriers that you have. With the above mentioned methodologies you can test all the Business Logic that you might have in production in a test rig.
Other then State Machines and the methods I explained above, I do not know any other way to do it that extensively.
Now lets look to the first files that is created for us, applicationContext-statemachine-customersearch.xml.
So the Spring Bean xml that is representing a State Machine will look something like this…
<bean id="CustomerSearchSM" class="org.salgar.swf_statemachine.impl.StateMachineImpl"
lazy-init="true" scope="flow">
<!-- aop:scoped-proxy proxy-target-class="false" / -->
<property name="name">
<bean class="org.salgar.swf_statemachine.enumeration.StateMachineEnumerationImpl"
factory-method="valueOf">
<constructor-arg>
<value>org.salgar.swf_statemachine.enumeration.StateMachineEnumerationImpl</value>
</constructor-arg>
<constructor-arg>
<value>CustomerSearchSM</value>
</constructor-arg>
</bean>
</property>
<property name="controlObjects">
<map>
<entry key="CustomerSearchSMControlObject" value-ref="CustomerSearchSMControlObject"/>
</map>
</property>
<property name="startState" ref="CustomerSearchSM.WAITING_CUSTOMERSEARCH_START"/>
<property name="existingStates">
<list>
<ref bean="CustomerSearchSM.WAITING_CUSTOMERSEARCH_START"/>
<ref bean="CustomerSearchSM.CUSTOMERSEARCH_RUNNING"/>
<ref bean="CustomerSearchSM.CUSTOMER_FOUND"/>
<ref bean="CustomerSearchSM.CUSTOMER_AUTHENTICATED"/>
<ref bean="CustomerSearchSM.CUSTOMER_JOINED"/>
<ref bean="CustomerSearchSM.ORDERS_LOADING"/>
</list>
</property>
</bean>
snippet 12
For ex, above you see Customer Search State Machine, his name is taken from the model and initialized in the Java Object via the Enumeration.
Then a Control Object will be defined in the Spring configuration (Actual implementation of this control object will lie in the next project.)
And the States that a State Machine has, will be defined in the Spring configuration.
And an Initial State that is defined start-up state of the State Machine when it is initiated via Spring.
As you see, Spring is totally enough to represent the information contained in UML Model.
Next part will contain the information about the States defined above. I am only placing one piece here ,not clutter too much.
<!-- STATES - CustomerSearchSM -->
<bean name="CustomerSearchSM.WAITING_CUSTOMERSEARCH_START" class="org.salgar.statemachine.domain.State">
<property name="name">
<bean class="org.salgar.swf_statemachine.enumeration.state.CustomerSearchSM_StateEnumerationImpl"
factory-method="valueOf">
<constructor-arg>
<value>
org.salgar.swf_statemachine.enumeration.state.CustomerSearchSM_StateEnumerationImpl
</value>
</constructor-arg>
<constructor-arg>
<value>WAITING_CUSTOMERSEARCH_START</value>
</constructor-arg>
</bean>
</property>
<property name="outgoingTransitions">
<list>
<!-- SearchRunningTransition -->
<ref bean="CustomerSearchSM.transition_WAITING_CUSTOMERSEARCH_START_CUSTOMERSEARCH_RUNNING"/>
</list>
</property>
<property name="incomingTransitions">
<list> </list>
</property>
</bean>
snippet 13
So beans name “CustomerSearchSM.WAITING_CUSTOMERSEARCH_START” defines to which State Machine this State belongs and the actual name of the state as defined in the UML Model, which will be represented by the Java Enumeration that is created by the M2T.
Next pieces of information displays which transition can occur to this State, with property ‘incomingTransitions’ and which transitions can occur from this state with property ‘outgoingTransitions’.
The next part defines the transitions that we defined in the UML Model.
<!-- TRANSITIONS -->
<!-- TRANSITION - SearchRunningTransition -->
<bean name="CustomerSearchSM.transition_WAITING_CUSTOMERSEARCH_START_CUSTOMERSEARCH_RUNNING"
class="org.salgar.swf_statemachine.impl.transition.TransitionImpl">
<property name="name" value="CustomerSearchSM.SearchRunningTransition"/>
<property name="sourceState" ref="CustomerSearchSM.WAITING_CUSTOMERSEARCH_START"/>
<property name="targetState" ref="CustomerSearchSM.CUSTOMERSEARCH_RUNNING"/>
<property name="eventType">
<bean class="org.salgar.swf_statemachine.enumeration.event.customersearchsm.CustomerSearchSM_EventEnumerationImpl"
factory-method="valueOf">
<constructor-arg>
<value>
org.salgar.swf_statemachine.enumeration.event.customersearchsm.CustomerSearchSM_EventEnumerationImpl
</value>
</constructor-arg>
<constructor-arg>
<value>onStartSearch</value>
</constructor-arg>
</bean>
</property>
<property name="guard" ref="defaultGuard"/>
<property name="action" ref="CustomerSearchSM.WAITING_CUSTOMERSEARCH_START.CUSTOMERSEARCH_RUNNING.SearchRunningTransition.action"/>
</bean>
snippet 14
Name field of the bean for Transition defines to which State Machine Transition belongs and from which State to which State it leads. In this case CustomerSearchSM.transition_WAITING_CUSTOMERSEARCH_START_CUSTOMERSEARCH_RUNNING belongs to CustomerSearchSM and it leads WAITING_CUSTOMERSEARCH_START to CUSTOMERSEARCH_RUNNING.
Additional it also defines which Event can trigger this transition over a Java Enumeration created by M2T which contains all the Events in the UML Model for this State Machine.
The property ‘guard’ is representing the object that should run, to decide that this Transition should run for this event or not. For the example above ‘defaultGuard’ which is a pass through Guard Condition that returns all the time true and it is only used if a specific Guard Condition is not annotated over the Transition in the UML Model.
A transition can also have an Action, which most of the time some logic that should occur during the transition.
In our case, it is defined on the action property.The notation CustomerSearchSM.WAITING_CUSTOMERSEARCH_START.CUSTOMERSEARCH_RUNNING.SearchRunningTransition.action‘ defines the information about which State Machine and for which Transition, this Action belongs, it also includes the information about from which State to which State this Transition occurs.
This whole information stored in UML Model as follow, if you select the transition from WAITING_CUSTOMERSEARCH_START to CUSTOMERSEARCH_RUNNING in the UML Model.
picture 9
You will see the following picture in Topcased.
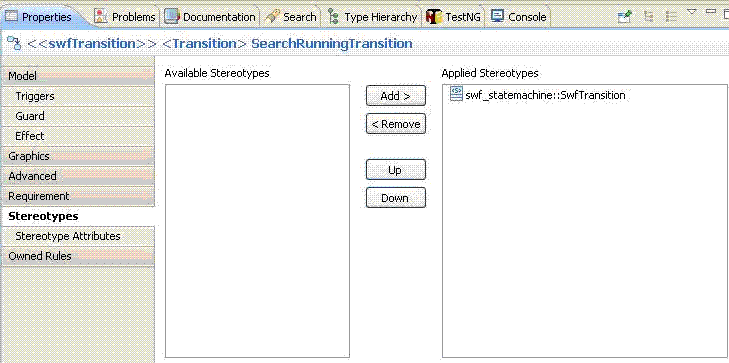
picture 10
In this picture ,you see that a custom Steoreotype (swf_statemachine::SwfTransition) that we defined before assigned to this Transition (I will explain in the Appendix- How to create and use custom Steorotypes).
This custom Steoreotype will contain the name of Java Class which will implement the Action of the Transition (also the Guard if one exist). When the M2T will read this information, it will instantiate the named Java Class in Spring but will leave the responsibility of implementing concrete class to the user (It is expected that this class lies in swf_statemachine_sm_model_impl project for the testablity purposes).

picture 11
In this case, a CustomerSearchRunningAction defined and M2T will place this information in Spring Configuration. CustomerSearchRunningAction.java class that we have to be create in swf_statemachine_sm_model_impl and will be responsible for initiating the search Action in the partner system.
Such a feature bring us to the thema of to be able to test rig our complete State Machine, instead of real implementation of the CustomerSearchRunningAction (which we would require an integration test environment) in a test project that we can implement a Mock version of the Action and unit test of all of our Use Cases in test rig with the help of a State Machine.
No other methodology and framework present at the moment such a possibility, the way the GUI and business logic coupled it nearly never lets that such a complete test to be applicable (even with the MVC you are not getting such a clear separation. Think about how much logic is always attached to the your backing bean and for that the difficulties you get to build test rigs).
As you may see from the above picture you also have a possibility to provide a Guard implementation, if no input given, M2T would place the name DefaultGuard class which will always return true.
swf_statemachine_sm_model_impl:
This project contains the implementation of our control objects, actions, guards necessary to implement the business cases of our application.
Everything organized under the java packages reflecting the name of the state machine.
In test directory, you can also place the mock implementations that we can use as previously mentioned Test Rig.
Following is a typical implementation of an Action in our object, which you can identify from the UML Diagram in the picture 5. This action occurs for the START_SEARCH event.
public class CustomerSearchRunningAction implements Action, Serializable {
private static final long serialVersionUID = -181796739393959337L;
public void processAction(Event event, AbstractStateMachine stateMachine) {
CustomerSearchCO customerSearchCO = (CustomerSearchCO) stateMachine
.getControlObject();
CustomerSearchStartEventPayload customerSearchStartEventPayload = (CustomerSearchStartEventPayload) event
.getPayload();
Event findCustomerSmEvent = new Event();
findCustomerSmEvent
.setEventType(FindCustomerSM_EventEnumerationImpl.onStartSearch);
findCustomerSmEvent.setPayload(customerSearchCO.getCustomerNumber());
findCustomerSmEvent.setSource(stateMachine);
AbstractStateMachine findCustomerStateMachine = (AbstractStateMachine) stateMachine
.findObjects(StateMachineEnumerationImpl.FindCustomerSM
.getStateMachineName());
findCustomerStateMachine.resetStateMachine();
findCustomerStateMachine.dispatch(findCustomerSmEvent);
CustomerSearchSMControlObjectAccessor
.processCustomerSearchRunningAction(
(CustomerSearchSMControlObject) customerSearchCO,
customerSearchStartEventPayload.getCustomerNumber());
}
}
snippet 15
When State Machine finds this action, it will call the processAction method with the parameters Event that triggered this Action (Event object that populated from the GUI Layer) and State Machine (which is the State Machine that action runs for).
By the way, while we are making Model Driven Software Development, we have another project, which I will explain after this project, called ‘swf_statemachine_techdemo_domain’ which is modelling the GUI Layer objects which has to organize the communication between State Machine and GUI Layer.
The payload ‘CustomerSearchStartEventPayload’ of our event object modelled in this project.
Now we are coming to another important subject, which is concept of Master and Slave State Machines.
Master / Slave State Machines
One problem, I previously mentioned is State Explosions (which you can see in this Appendix), which occurs when our use cases are getting more and more complex. The number of states inside of the State Machine increases and the possibility of these States interacting with each other increase also and after certain number of States, this situation becomes uncontrollable and this is called State Explosion.
Theoretically it is possible to define all States in one single State Machine but in practical programming it is better not to.
We should divide our use cases and uses smaller State Machines to represent them.
For our case here, it manifests itself as following.
To realise a customer search, we will have a State Machine modelling the GUI Layer and one State Machine that models and controls the search customer functionality provided by an external system.
In this case the State Machine controlling the GUI layer would be the Master State Machine and State Machine that is controlling the customer search functionality would be slave one.
FindCustomerSM State Machine will be responsible encapsulating the functionality belongs searching a customer.

picture 12
This State Machine is small enough to be self contained, its only responsibility is to control the partner system which is executing findCustomer process. Any other State Machine that wants to interact with this partner system should only communicate with this State Machine and doesn’t have to know anything about the partner system.
AbstractStateMachine findCustomerStateMachine = (AbstractStateMachine) stateMachine .findObjects(StateMachineEnumerationImpl.FindCustomerSM .getStateMachineName()); findCustomerStateMachine.resetStateMachine(); findCustomerStateMachine.dispatch(findCustomerSmEvent);
snippet 16
From the above code snippet, we see that Master State Machine gets the Slave, send the event to initialize the customer search.
In case the customer search is successful, CUSTOMER_FOUND event will be triggered and the action in the following snippet will be executed.
public class FindCustomerCustomerFoundAction implements Action {
public void processAction(Event event, AbstractStateMachine stateMachine) {
Event customerFoundEvent = new Event();
customerFoundEvent
.setEventType(CustomerSearchSM_EventEnumerationImpl.onCustomerFound);
customerFoundEvent.setPayload(event.getPayload());
((FindCustomerSMControlObject) stateMachine.getControlObject())
.getMasterStateMachine().handleEvent(customerFoundEvent);
}
}
snippet 17
Slave State Machine, by configuration (via Spring Application Context) knows that it is a Slave State Machine and it should report at End States to the Master State Machine.
In this case, the action processed with CUSTOMER_FOUND sends an Event to the Master State Machine, which will change the Master State Machine to CUSTOMER_FOUND State from CUSTOMER_SEARCH_RUNNING.
Now this is the ideal case, we searched a customer and found a customer. What should happen if we get a timeout? How the system should behave?
- Now this is a fine point, there is a really useful tip here you can use against State Explosion.
We can define naturally as much as necessary States in Customer Search State Machine, so that means we can add Error States.
Then again lots of the existing States will have to be connected to these new States via transitions and depending to the nature of the error, there must be more then one extra State (Timeout Error, Connection Error, etc) which will make the things worst. This will cause a State Explosion, in the previous case, we identified State Explosion can be caused with the communication with Partner Systems and we solve that problem with Master/Slave State Machines but we can’t apply this solution to here because Errors are inheriting part of the Customer Search use case.
There is another concept called Nested State Machines, based on ‘Ultimate Hook’ pattern, if an Event is not handled in most specialized State Machine then it should be propagated back in the Nested State Machine chain.
We can explain this with a very known example, everybody knows how the Windows Operating System’s event mechanism works, for ex, a click event.
In general, windows OS defines a general click event, if any application code provided by the developer is interested with this event, he/should register for the event in the application code.
If there is no application code that is handling the event, it is propagated back to Windows OS so it can apply its default behaviour. Same pattern is valid for the Nested State Machines.
Our GUI has standard error messages, one for Timeout, one for Connection problems, instead of handling and representing these States in Customer Search State Machine, if we will have Error State Machine and it will nest Customer Search State Machine, every time Customer Search State Machine receives an event that it cannot handle itself, is going to be propagated to Error State Machine to be handled there.
This will prevent the State Explosion, instead of every State in the nested State Machine having transitions to these error states only Host State Machine builds these transitions, when nested State Machine can’t handle event and find a Transition it will delegate to Host State Machine and it will handle it.
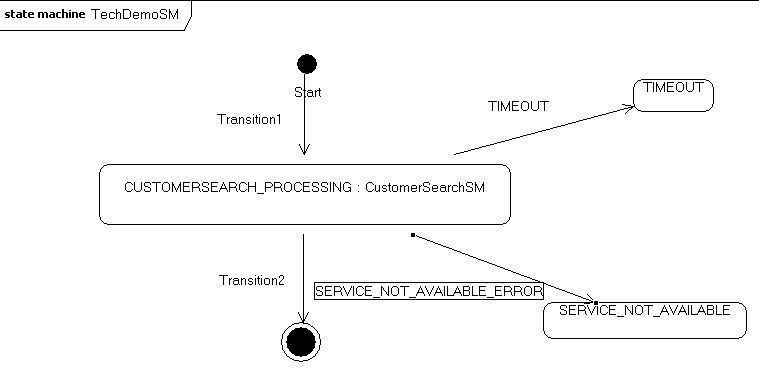
picture 13
You can see above in a State Machine Diagram what we mean. TechDemoSM is our top StateMachine containing all of our use cases. You can see in the diagram that we have a CUSTOMERSEARCH_PROCESSING State containing the Nested State Machine Customer Search State Machine.
When we are processing a Customer Search use case, we will be in CUSTOMERSEARCH_PROCESSING State and all the Event’s that TechDemoSM receives will be delegated to this State. Now this State doesn’t have an Transition for this Event but it has a Nested State Machine, CustomerSearchSM, next thing to do is to ask to this State Machine that it has a transition for this Event or not.
If Customer Seach State Machine knows the Event have a Transition for it, it will process the Event. If it doesn’t have a Transition for the Event, it will re-delegate to the upper State Machine, in this case to TechDemoSM.
picture 14
Now let’s assume, CustomerSearchSM is in CUSTOMERSEARCH_RUNNING State and we received CUSTOMER_FOUND Event, the Event will be first delivered to the TechDemoSM, while we are in CUSTOMERSEARCH_PROCESSING State in TechDemoSM Event will be transferred to the CustomerSearchSM and it knows how to handle CUSTOMER_FOUND Event.
Think about the following scenario, we are again in CUSTOMERSEARCH_RUNNING State but we are getting a SERVICE_NOT_AVAILABLE Event. Now we could naturally modelled a State in CustomerSearchSM to handle this event but most probably other States will need a transition to this State also, like ORDER_LOADING when it experiences an error case then it will need this transition also.
This is the part cluttering of the State Machine and State Explosions starts, the solution that our Nested State Machine provides, the moment it discovers it can’t handle this Event, it propagates it back to the TechDemoSM and luckily it has a Transition to the SERVICE_NOT_AVAILABLE State to handle it.
I guess with this sample you can see the power of the Nested State Machines.
Test Rigs:
Now we always stated that one of the biggest advantages of this methodology is to be able to test whole business case in a Test Rig.
Our completed Techdemo application GUI will look like as following per State (if you look to the State Machine Diagram).
WAITING_FOR_CUSTOMERSEARCH_START

picture 15
if you enter ‘123456789’ for the search parameter, you can proceed with customer search.
CUSTOMERSEARCH_RUNNING

picture 16
CUSTOMER_FOUND

picture 17
CUSTOMER_AUTHENTICATED

picture 18
ORDERS_LOADING

picture 19
CUSTOMER_JOINED

picture 20
when the following URL is called.
http://localhost:8080/swf_statemachine_techdemo-1.0-SNAPSHOT/spring/customersearch
The application is sensitive to only one customer number ‘123456789’ 🙂 so if you search this customer number you would be able to access to further states.
As you see every step has really good defined view states, which GUI elements are visible and which are not. With this information we can write our Unit Test.
Following is a unit test testing WAITING_FOR_CUSTOMERSEARCH_START to CUSTOMER_FOUND.
If you examine the JSF pages for the above displayed GUI elements you will see that their render methods consist of checking the value of the State Machine control objects.
For ex. from customerSearchInput.xhtml
<p:outputPanel id="customerSearchInputLayout" ajaxRendered="true"
layout="block" style="border:1px solid" rendered="#{customerSearchInputBB.customerSearchInputLayoutRendered}">
snippet 18
or customerSearchRunning.xhtml
<p:outputPanel id="customerSearchRunning-panel_layout" ajaxRendered="true"
layout="block" style="border:1px solid" rendered="#{customerSearchRunningBB.customerSearchRunningPanelRendered}">
snippet 19
and customerSearchFound.xhtml
<p:outputPanel id="customerSearchFound-panel" ajaxRendered="true"
layout="block" style="border:1px solid" rendered="#{customerSearchFoundBB.customerSearchFoundPanelRendered}">
snippet 20
The backing beans methods are not doing anything other then relaying the values defined in the control objects of the State Machines.
public boolean isCustomerSearchInputLayoutRendered() {
CustomerSearchInputCO customerSearchInputCO = (CustomerSearchInputCO) stateMachine
.getControlObject();
return customerSearchInputCO.getRenderCustomerSearchInput();
}
snippet 21
A detailed explanation of how exactly the Unit Tests should look like you can find in the following Appendix.
swf_statemachine_techdemo_domain:
This project contains artifacts necessary for the communication from the object in our GUI Layer (swf_statemachine_techdemo) and State Machine level (swf_statemachine_sm_model_impl) like Customer, Order object which are necessary for our GUI Layer to display the information and also necessary in State Machine Layer so that State Machines can populate the information.
But also while we practicing here Model Driven Architecture (MDA) the objects that are used in the GUI Layer (but nothing to do in State Machine Layer, modelled here instead in Tech Demo project) like Manager’s (CustomerManager, OrderManager), event payloads (CustomerSearchStateEventPayload) and asynchronous Event Listeners for Comet functionality (the way the GUI Layer/Browser receive event from the State Machines to inform there is a State change and the information is ready).
The class diagrams looks like as following.
For Domain Object’s

picture 21
For Manager’s
picture 22
For Event Payload’s

picture 23
The necessary Java Code are created via Fornax M2T Java Template ‘s for these UML Objects.
swf_statemachine_techdemo:
This is the GUI layer of our project, it is a JSF project with Primefaces as the JSF implementation.
Most interesting part of this project is how Spring Webflow is helping to integrate our State Machine with JSF lifecycles and events.
I think it is best to start to analyze the structure of the application from web.xml which will be a statement of the technologies we use in the project.
First we have to initialize naturally our Spring Application Context for Spring MVC, Spring Webflow and our State Machines.
<servlet> <servlet-name>spring_mvc</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <init-param> <param-name>contextConfigLocation</param-name> <param-value>/WEB-INF/config/webmvc-config.xml, /WEB-INF/config/webflow-config.xml, /WEB-INF/config/applicationContext-customersearch.xml, classpath:/META-INF/customersearch/applicationContext-statemachine-customersearch.xml, classpath:/META-INF/customersearch/applicationContext-statemachine-customersearch-guards.xml, classpath:/META-INF/customersearch/applicationContext-statemachine-customersearch-controlobjects.xml, classpath:/META-INF/findcustomer/applicationContext-statemachine-findcustomer.xml, classpath:/META-INF/findcustomer/applicationContext-statemachine-findcustomer-guards.xml, classpath:/META-INF/findcustomer/applicationContext-statemachine-findcustomer-controlobjects.xml, classpath:/META-INF/findorders/applicationContext-statemachine-findorders.xml, classpath:/META-INF/findorders/applicationContext-statemachine-findorders-guards.xml, classpath:/META-INF/findorders/applicationContext-statemachine-findorders-controlobjects.xml /WEB-INF/config/applicationContext-manager.xml</param-value> </init-param> <load-on-startup>1</load-on-startup> </servlet>
snippet 22
A 2nd Servlet other then ordinary ones like FacesServlet and Primefaces is the following
<servlet>
<servlet-name>Push Servlet</servlet-name>
<servlet-class>org.primefaces.push.PushServlet</servlet-class>
</servlet>
snippet 23
PushServlet is responsible to establish the asynchronous communication between Client Browser and our Application Server based on Comet Technologies.
As you configuration in web.xml is quite simple.
Next we have too look to the setup of the Spring Webflow, first webmvc-config.xml.
<bean class="org.springframework.webflow.mvc.servlet.FlowHandlerMapping"> <property name="flowRegistry" ref="flowRegistry" /> <property name="defaultHandler"> <!-- If no flow match, map path to a view to render; e.g. the "/intro" path would map to the view named "intro" --> <bean class="org.springframework.web.servlet.mvc.UrlFilenameViewController" /> </property> </bean>
snippet 23
First while we have to redirect the request we get to the Spring WebFlow so we have to configure following in Spring MVC properties.
We have to set the flowRegistry (which keeps account of which flows exist for us) of the Spring Webflow (those are configured in webflow-config.xml)
Then we configure where is our JSF Views/Files are placed.
<bean id="faceletsViewResolver" class="org.springframework.web.servlet.view.UrlBasedViewResolver"> <property name="viewClass" value="org.springframework.faces.mvc.JsfView" /> <property name="prefix" value="/WEB-INF/" /> <property name="suffix" value=".xhtml" /> </bean>
snippet 24
And we have to configure how JSF navigation events will be transferred to the Spring Webflow.
<bean class="org.springframework.faces.webflow.JsfFlowHandlerAdapter">
<property name="flowExecutor" ref="flowExecutor" />
</bean>
snippet 25
And lets look to how the WebFlow configuration works out(webflow-config.xml).
<flow:flow-executor id="flowExecutor"> <flow:flow-execution-listeners> <flow:listener ref="facesContextListener" /> </flow:flow-execution-listeners> </flow:flow-executor>
snippet 26
This configuration ensures that Spring Webflow receives the JSF Lifecycle events and able to execute Spring Webflow flows.
Our Flow Registry telling Spring Web Flow where to look to initialize our Spring Web Flows.
<flow:flow-registry id="flowRegistry" flow-builder-services="facesFlowBuilderServices"> <flow:flow-location path="/WEB-INF/flows/customersearch/customersearch.xml" /> </flow:flow-registry>
snippet 27
In this case we are loading our Spring Web Flow configuration from WEB-INF/flows directory.
Configuration of the Spring Web Flow and JSF integration.
<faces:flow-builder-services id="facesFlowBuilderServices" />
snippet 28
Now lets look to the to our Flow configuration.
<?xml version="1.0" encoding="UTF-8"?>
<flow xmlns="http://www.springframework.org/schema/webflow"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/webflow
http://www.springframework.org/schema/webflow/spring-webflow-2.0.xsd">
<on-start>
<evaluate expression="CustomerSearchSM.resetStateMachine()"/>
</on-start>
<view-state id="customerSearch">
<transition on="onStartCustomerSearch" history="invalidate">
<evaluate expression="customerSearchInputBB.searchCustomer()"/>
</transition>
<transition on="onCustomerAuthenticated" history="invalidate">
<evaluate expression="customerSearchAuthenticationBB.customerGivesAuthentication()"></evaluate>
</transition>
<transition on="onCustomerJoined" history="invalidate">
<evaluate expression="customerSearchJoinBB.customerJoined()"></evaluate>
</transition>
</view-state>
</flow>
snippet 29
You can see that Web Flow configuration is quite small. At this point you might think why I was saying Spring WebFlow has such a big role in our project.
If you look to this configuration file you will see that Spring Flow handles two important aspect for our project.
First it is initializing the State Machine every time our business case starts from the beginning, under the control of ‘on-start’ tag (it is the concept called ‘conversations’ in Spring Web Flow. Inside of your web sessions, every Business Case is started inside of a separated memory contention, if you run several instance of your Business Case in same web session, it will work without their state variables corrupting each other). This can be quite a big headache, if we have to figure out this our self with the JSF.
<on-start> <evaluate expression="CustomerSearchSM.resetStateMachine()"/> </on-start>
snippet 30
Secondly, it transfers user events from the GUI (User clicking buttons and so) to our business logic/State Machine. Instead of fighting with JSF to receive this events from JSF, we are receiving over Spring Web Flow.
Another major advantage, in our JSF pages, only names of the Events defined in the State Machine UML diagrams are mentioned, for ex, ‘onStartCustomerSearch’, ‘onCustomerAuthenticated’, ‘onCustomerJoined’. JSF code doesn’t reference any backing bean or any State Machine. It means that by changing Spring Web Flow definition file, you can change completely the implementation of your business logic without changing a single line in your JSF files. It brings quite impressive level of re-usability.
If you look to the ‘customSearchInput.xhtml’ you see the following JSF commandButton element there.
<p:commandButton id="customerSearchStart" value="Search" action="onStartCustomerSearch" ajax="true" update="customerSearch-form,customerSearchRunning-panel_empty_layout,handlePuplishRemoteCommand"> </p:commandButton>
snippet 31
As you see there is no direct reference to any Backing Bean or Spring Bean, what this provides, Spring Webflow intercepting a JSF event, interprets it with the help of the Spring Webflow definitions and initiates the correct Event for our State Machine.
Spring Webflow looks from the request, which JSF page is requested (in this case customerSearch.xhtml) and maps it to the following Spring Webflow configuration.
<view-state id="customerSearch">
snippet 32
and transitions defined for this view state.
<transition on="onStartCustomerSearch" history="invalidate"> <evaluate expression="customerSearchInputBB.searchCustomer()"/> </transition>
snippet 33
In this snippet, it is configured to call the searchCustomer method on the customerSearchInputBB Backing Bean but it can be easily configured to another method on another Backing Bean. If we change our WebFlow file we can make the GUI reference a complete different State Machine/Business Logic implementation without changing one lines of code in .xhtml files.
This method will send the ‘onStartSearch’ event to the State Machine.
The method looks like following.
public void searchCustomer() {
log.info("We are searching customer!");
Event event = new Event();
event.setEventType(CustomerSearchSM_EventEnumerationImpl.onStartSearch);
CustomerSearchStartEventPayload customerSearchStartEventPayload = new CustomerSearchStartEventPayload();
customerSearchStartEventPayload.setCustomerNumber(customerNumber);
event.setPayload(customerSearchStartEventPayload);
stateMachine.handleEvent(event);
}
snippet 34
The application GUI is built with small .xhtml fragments, put it together in customerSearch.xhtml with facelet include statements for re-usability purposes. If you are valuing re-usability (like using order table in several other places in your application) you can include it to other pages/use cases. Re-usability is also guaranteed with use of interfaces when accessing to the Control Objects of the State Machine so implementation can be changed quite easily, which look like this for ‘customerSearchOrder.xhtml’.
<?xml version="1.0" encoding="ISO-8859-1"?>
<ui:composition xmlns="http://www.w3.org/1999/xhtml"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:p="http://primefaces.prime.com.tr/ui">
<p:outputPanel id="customerSearchOrderLoading-empty-panel">
<p:outputPanel id="customerSearchOrderLoading-panel" ajaxRendered="true"
layout="block" style="border:1px solid" rendered="#{customerSearchOrderBB.customerSearchOrderLoadingPanelRendered}">
<p1>Please wait that the orders would load!!!!</p1>
</p:outputPanel>
</p:outputPanel>
<p:outputPanel id="customerSearchOrder-empty-panel">
<p:outputPanel id="customerSearchOrder-panel" ajaxRendered="true"
layout="block" style="border:1px solid" rendered="#{customerSearchOrderBB.customerSearchOrderPanelRendered}">
<h:form id="ordersForm">
<p:dataTable id="ordersTable" var="order" value="#{customerSearchOrderBB.orders}">
<p:column>
<f:facet name="header">
Order Id:
</f:facet>
<h:outputText value="#{order.id}"/>
</p:column>
<p:column>
<f:facet name="header">
Order Date:
</f:facet>
<h:outputText value="#{order.date}"/>
</p:column>
<p:column>
<f:facet name="header">
Order Description:
</f:facet>
<h:outputText value="#{order.description}"/>
</p:column>
</p:dataTable>
</h:form>
</p:outputPanel>
</p:outputPanel>
</ui:composition>
snippet 35
The critical point in the code is the following.
<p:dataTable id="ordersTable" var="order" value="#{customerSearchOrderBB.orders}">
snippet 36
Looks like this in the Backing Bean.
public class CustomerSearchOrderBB {
private StateMachine stateMachine;
@SuppressWarnings("unchecked")
public List<Order> getOrders() {
return ((CustomerSearchOrderCO) stateMachine.getControlObject())
.getCustomerOrders();
}
public boolean isCustomerSearchOrderPanelRendered() {
return ((CustomerSearchOrderCO) stateMachine.getControlObject())
.getRenderCustomerOrders();
}
public boolean isCustomerSearchOrderLoadingPanelRendered() {
return ((CustomerSearchOrderCO) stateMachine.getControlObject())
.getRenderCustomerOrderLoading();
}
public void setStateMachine(StateMachine stateMachine) {
this.stateMachine = stateMachine;
}
}
snippet 37
We only access to the State Machine Control Objects over Interfaces so that we can always change the implementation but use the same .xhtml fragment (lets say you want to show Order for the last 3 month and you want to re-use this.xhtml fragment part it is totally possible).
When all fragments included to the ‘customerSearch.xhtml’ it look like as following.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:fn="http://java.sun.com/jsp/jstl/functions"
xmlns:p="http://primefaces.org/ui">
<f:view contentType="text/html" encoding="UTF-8">
<h:head>
<title>Customer Search - Spring WebFlow - Primefaces - State Machine Demo</title>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type" />
</h:head>
<body>
<p:outputPanel ajaxRendered="true" id="handlePuplishRemoteCommand">
<script id="sc1" type="text/javascript" language="Javascript">
function handlePublishInternal() {
PrimeFaces.ajax.AjaxRequest('/swf_statemachine_techdemo-1.0-SNAPSHOT/spring/customersearch?jsessionId=#{externalContext.nativeRequest.session.id}&execution=#{flowExecutionContext.key}',{formId:'customerSearchCustomerDetail_form',async:true,global:true,source:'customerSearchCustomerDetail_form:customerSearchViewCustomerDetail',process:'@all',update:'#{customerSearchBB.customerSearchJavaScriptRenderPanels}'});return false;
};
</script>
</p:outputPanel>
<ui:include src="customerSearchInput.xhtml" />
<ui:include src="customerSearchRunning.xhtml" />
<ui:include src="customerSearchFound.xhtml" />
<ui:include src="customerSearchAuthentication.xhtml" />
<ui:include src="customerSearchJoin.xhtml" />
<ui:include src="customerSearchOrder.xhtml" />
<h:form id="customerSearchCustomerDetail_form">
<p:socket id="cometPush" channel="/customer_search_result_#{externalContext.nativeRequest.session.id}_#{flowExecutionContext.key}" >
<p:ajax event="message" update="#{customerSearchBB.customerSearchJavaScriptRenderPanels}" />
</p:socket>
<p:commandButton id="customerSearchViewCustomerDetail" value="Continue"
ajax="true" update=":customerSearchRunning-panel_empty_layout,:customerSearchFound-empty-panel,:customerSearchAuthentication-empty-panel">
</p:commandButton>
</h:form>
</body>
</f:view>
</html>
snippet 38
An interesting element here is the ‘p:socket’ tag, which is providing Asynchronous AJAX (Comet/Atmosphere) communication between the browser and the server. When an interesting Event occurs for the GUI and the GUI has to be refreshed. The server will notify the GUI over this component.
In our case, we search the customer over the Partner System when the customer found, server will notify us. p:socket tag implements exactly this. p:socket will listen the channel defined in its attribute ‘/customer_search_result’ and react to this message arriving to this channel. If a message received it will trigger an ajax event via ‘
‘ and render areas defined by our State Machine.Here, one word of warning, p:socket channel, acts like a topic, so several web client can subscribe to this topic, it is web application wide. So if you don’t want that all the client of your web application receives the message, you should configure the channels to be unique. Here I did this by first adding the sessionId to channel name ‘#{externalContext.nativeRequest.session.id}’, plus while we are using Spring Web Flow, flowId to support the multi tab behavior ‘#{flowExecutionContext.key}’.
You can find more details about Comet/Atmosphere in the following Appendix.
swf_statemachine_xpand:
In this project, we have the necessary files containing the DSL of the M2T to interpret UML file and create the specific language we want. In our case, it is create Java and Spring code.
For the creation of Java code we are using the some prepared libraries from Fornax.
If you look to the template for the Java Code (stateMachineEnumeration.xpt), which only scans the model and creates Enumerations for all the State Machine, State and Event names.
«DEFINE Root FOR uml::Model»
«FILE "org/salgar/swf_statemachine/enumeration/StateMachineEnumerationImpl.java"»
package org.salgar.swf_statemachine.enumeration;
import org.salgar.statemachine.domain.StateMachineEnumeration;
public enum StateMachineEnumerationImpl implements
StateMachineEnumeration {
«FOREACH allOwnedElements().typeSelect(uml::StateMachine) AS stateMachine SEPARATOR ','»
«stateMachine.name»("«stateMachine.name»")
«EXPAND StateEnumeration(stateMachine)»
«EXPAND EventEnumeration(stateMachine)»
«ENDFOREACH»;
private String name;
StateMachineEnumerationImpl(String name) {
this.name = name;
}
public String getStateMachineName() {
return this.name;
}
@Override
public String toString() {
return this.name;
}
}
«ENDFILE»
«ENDDEFINE»
snippet 39
If we analyze the M2T template,
«DEFINE Root FOR uml::Model» says for every element in the model make a loop and process the element. «FOREACH allOwnedElements().typeSelect(uml::StateMachine) AS stateMachine SEPARATOR ','» states for all the Elements on the model with the type ‘uml::StateMachine’ run a loop and apply templates, which are «EXPAND StateEnumeration(stateMachine)» and «EXPAND EventEnumeration(stateMachine)» these templates you can find in the same file. To give a feel about them, I will go over one of them quickly. «DEFINE StateEnumeration(uml::StateMachine sm) FOR uml::Model» Following defines that this template will process every uml::StateMachine in out uml::Model. «FOREACH sm.allOwnedElements().typeSelect(uml::State) AS state SEPARATOR ','» here, we will search all the uml::StateMachine to find all of its states. «IF state.submachine != null» ,«EXPAND SubStateMachineStateEnumeration(sm, state.submachine)» «ENDIF»
and here if we can find a Sub StateMachine for the State we will expand that also.
This is the basic idea about Xpand/M2T templates, find specific elements in the UML models and loop over them and expand them.
We can now look what is happening in Xpand template which is creating the Spring Files (which is quite complex, compared to templates of the Enumerations).
«DEFINE Spring FOR uml::Model» «EXPAND Root(this) FOREACH (List[uml::Package])ownedElement» «EXPAND SteorotypeGuardsActions(this) FOREACH (List[uml::Package])ownedElement» «EXPAND ControlObjects(this) FOREACH (List[uml::Package])ownedElement» «ENDDEFINE»
snippet 40
Above template is searching for the uml::Package’s we have in the uml::Model (while we organized our State Machines in uml::Packages) and the it tries to creates Spring xml configuration files.
«DEFINE Root(uml::Model model) FOR uml::Package» «IF ownedType.typeSelect(uml::StateMachine).isEmpty==false» «FILE "META-INF/" + name + "/applicationContext-statemachine-"+name+".xml"» <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd "> «EXPAND StateMachines(model) FOREACH ownedType.typeSelect(uml::StateMachine)» <bean name="defaultGuard" class="org.salgar.swf_statemachine.impl.guard.DefaultGuardImpl" /> <bean name="defaultAction" class="org.salgar.swf_statemachine.impl.action.DefaultAction" /> </beans> «EXPAND Root(model) FOREACH nestedPackage» «ENDFILE» «ELSE» «EXPAND Root(model) FOREACH nestedPackage» «ENDIF» «ENDDEFINE»
snippet 41
This part of the template searches inside of the every uml::Package for the instances of uml::StateMachine so it can further process them, if a package does not contain a uml::StateMachine it further searches nestedPackages.
If it finds an uml::StateMachine it will execute the following Template
«DEFINE StateMachines(uml::Model model) FOR uml::StateMachine»
«IF this.getAppliedStereotype("swf_statemachine::SwfStateMachine")!= null»
«IF !this.getValue(this.getAppliedStereotype("swf_statemachine::SwfStateMachine"),"submachine")»
<!-- «name.toFirstUpper()» State Machine -->
<bean id="«name»" class="org.salgar.swf_statemachine.impl.StateMachineImpl" lazy-init="true"
«IF this.getAppliedStereotype("swf_statemachine::SwfStateMachine")!=null»
scope="«this.getValue(this.getAppliedStereotype("swf_statemachine::SwfStateMachine"),"Scope").name»"
«ENDIF»
>
«LET name AS localName»
«EXPAND StateMachinesCommon(model, this, localName)»
«ENDLET»
«ENDIF»
«ENDIF»
«ENDDEFINE»
snippet 42
Above template will create the necessary xml configuration for the State Machine and further elements of it (like States, Transitions, Actions, Guards, etc…). One interesting thing is how we interpret the Steorotypes and its properties. Steorotypes as you may remember the elements we use for the information that we can’t represent with standard UML elements (You can find more information about UML Steorotypes in the following Appendix). In this case our custom Actions, Guards and signals for Sub StateMachines (Nested StateMachines).
«IF this.getAppliedStereotype("swf_statemachine::SwfStateMachine")!= null» «IF !this.getValue(this.getAppliedStereotype("swf_statemachine::SwfStateMachine"),"submachine")»
snippet 43
I will not further analyze this Xpand templates here because it will clutter the discussion and the rest I think is self explanatory enough. If there will be further questions, I can expand this part in an Appendix.
swf_statemachine_fornax_extensions:
Fornax is a project providing out of the box M2T templates for Java Code creation (if you interested with Model Driven Software Development you can get nice Xpand templates for Spring and Hibernate also).
We are using Fornax Java Template for creating the Java code for Domain objects, there are some places we have to modify the code creation, for ex.
Xpand use the concept of Aspects like Java programming, you can pick Xpand Template method and create and Aspect and modify its behaviour.
«AROUND org::fornax::cartridges::uml2::javabasic::m2t::Association::attribute FOR uml::Classifier» «FOREACH AllAssociations().typeSelect(uml::Association) AS ass» «LET ass.visibility AS assocationVisiblity» «FOREACH ass.ownedEnd.select(e|e.type.name!=name) AS a» «IF getVisiblityName(assocationVisiblity) != 'public'» «EXPAND field(assocationVisiblity) FOR a» «ELSE» «EXPAND org::fornax::cartridges::uml2::javabasic::m2t::Association::field FOR a» «ENDIF» «ENDFOREACH» «ENDLET» «ENDFOREACH» «ENDAROUND»
snippet 44
Around Advice in javaBasicAssociationAdvices.xpt modifies the behaviour of the org::fornax::cartridges::uml2::javabasic::m2t::Association::attribute method in the Fornax Templates and implements our custom code creation.
In this case Fornax did not generate the code for Association Types (Collections) other then ‘public’ classifier so we have to modify Fornax behaviour here with our custom behaviour.
One other really powerfull mechanism we can define custom utility functions with Java Code to make the templating much easier.
We defined the following utility method in .ext file(M2T file type for extensions) .
String getVisiblityName(uml::VisibilityKind visibilityKind) : JAVA org.salgar.swf_statemachine.extensions.SwfStatemachineExtensions.getVisiblityName(org.eclipse.uml2.uml.VisibilityKind);
snippet 45
Which references to a Java Method defined in class SwfStatemachineExtensions.
public class SwfStatemachineExtensions {
public static String getVisiblityName(VisibilityKind visibilityKind) {
return visibilityKind.getLiteral();
}
}
snippet 46
Only thing that you have to pay attention in this method, it must be a static Method.
Conclusion:
I hope I reach my goal my to show there is a practical way to use UML and Model Driven Software for a web GUI projects, which some would not find practicable or reasonable before this blog.
The challenges of Web Application programming are quite different then the ones we have 5 years ago. The technologies from those eras forced us to use simple mono applications.
Today Ajax world, loads more and more responsibilities to the web applications, combined with connected nature of the businesses that we have at the moment, thanks to SOA and Cloud technologies, methods that are seen obsolete like Spring Web Flow, State Machines, UML, Model Driven Software Development can be quite relevant and helpful to conquer the challenges of the Web 2 the Ajaxified Web.
Appendix:
-State Machine
State Machines, better said, Final State Machines are containers to save status of something in giving point of the time. It has countable amount of states, there is the word Finite State is coming. In a giving FSM all states for all uses cases are known.
And a FSM can be in an one State a time, the State it is in at any given time is called the current State. It can change from one State to another when initiated by a triggering event and a condition, this called a transition. A particular FSM is defined by a list of its states and triggering condition for each transition.
State defines the persistent information of the objects that are dedicated for. For ex, a water cooker, if the water is cooler then defined value the water cooker is ON state, if the water is hotter then the predefined temperature then it is on OFF State.
A transition is the passage from one state to another, in this case going from ON state to OFF state which triggered from an event; a good example would be sensor telling that the water is too hot or too cold.
A transition can have a guard condition if a State lead from one possible State to several other States, for ex Water is too cold and the State must go from OFF to EXTRA POWER ON State to heat the water more quickly or the water is not that cold it can just go to ON State. This decision mechanism is called Guard which help to decide which Transition to take.
When State Machines gets a signal that it has to switch from one state to another one and Transition is decided an Action will be executed to realise necessary operations. For ex, if we are going to ON State in our water cooker then may be servo has to push the magnet coil.
-State Explosion
If you read everything above you might think it is easy to design and use a State Machine but there are some traps on the way.
As long as things stay small in scope you would not have that much problem but when the numbers of use cases are starting to increase you will have start experiencing following problem. It would be theoretically possible every State in your State Machine can have a transition to another State which will increase the number of transitions exponentially.
This point really limited the popularity of State Machines in current software development methods. The standard method to prevent this is a ‘divide and conquer’ strategy. We should distribute our use cases to get smaller State Machines model that way.
Combined with the previously explained Sub State Machine concept, in which when a State Machine receives an event, it will first check it for its in current State a Sub State Machine exist or not. If yes then it will delegate this Event to this Sub State Machine and expects to handle it and only to react to this Event if this Sub State Machine could not handle it.
This way Sub State Machine will have only transitions to the States under its control and would not know anything about outside world and containing State Machine will only have Transition’s for its own States. This will drastically reduce the number of Transition’s that exists in the system and prevent the State Explosion.
If your State Diagram’s start looking like as the following, you are really in big danger to running to the State Explosion problem.

StateExplosionStateMachine
picture 24
It is time to divide and conquer the problem.
A better solution would be the following.

picture 25

picture 26
You can see here what we mean with Nested State Machines. If we will try to model everything in one single State Machine we would have the Spagetti we show in the picture 24.
If we divide to problem to two different State Machine’s everything looks much better isn’t. This is also good opportunity to explain ‘Ultimate Hook’ pattern.
With the Nested State Machine following will happen, State Machine that you see in picture will get an event, in the case it can’t find a Transition to the Event it receive, it will check the current State contains a Nested State Machine, in our case STATE_WORKING has a Nested State Machine, so the event will be transferred there and this State Machine handles the transition from STATE_A to STATE_B.
Now we are in State Explosion State Machine an Event occurs that signals an error condition but State B has no transition navigating to an error condition, so when Nested State Machine will not able to find any transition it will delegate the event again to the containing State Machine which luckily has a transition to ERROR_1 State to handle the event.
– Multiple Browser Tabs and Spring Flows
One point that Spring Web Flow can support our concept is the data scope
‘flow’.
The nightmare of the Ajax Web Applications is the multi tab behaviour of the modern web browsers. Web application that are reacting to multiple events the global data containers is a huge problem because if the user starts another tab in the browser and start triggering additional events in the same session, global data containers will cause huge chaos.
Think about it, you are logged to your internet banking web site, you are doing operations in one tab and you decided to start a new tab in the browser and start triggering other operations which would your change account balance. How should the web application react, it should let you modify simultaneously or try to isolate things. I can tell you for the sake of you bank account, it should better isolate it.
For this purpose, Spring Web Flow presents ‘flow’ scope, when you define your Web Flow you define the entry points of your flow, when these entry points are passed, Spring Web Flow create these containers which would only hold the value of your data containers marked ‘flow scope’ in Spring Definition files.
This practically means, if you start two tabs in your browser and you trigger to entry events, this two tabs will only see their version of data containers in the flow.
Now this is a really nice future from Spring Flow but it has one annoyance, if you have lots data that you have to contain in your application, you should start tagging everything with this ‘flow scope’ which can be quite annoying.
Our approach here brings us one step forward then what Spring Web Flow can offer us. Our State Machine is our data container that representing the whole state of our application so to mark it as ‘flow scope’ would be enough to make our all application flow sensitive.
Only thing we have to do is to decorate our State Machine in UML Model with a Steorotype include the flow property as you can see in the below picture.

picture 27

picture 28
If you apply this option you will get the behaviour explained above.
There is one implementation point that I have to mention here. Normally if something tagged as ‘flow scope’ Spring Web Flow apply the following behaviour with every Web Request Spring Web Flow restores and persist the Flow with default Spring Web Flow configuration. Spring Web Flow before sending the answer of the Web Request, it use Java Serialisation to persist the state of the object marked as flow scope in the Spring configuration. When a new request comes for the same flow, it restores the object from this serialised object. Spring Webflow does that to remember several historical snapshots of this object.
Unfortunately this model does not fit us. Our State Machine continues to live and respond to the events even after the Web Request from the client answered (We called a partner system during the web request and the answer from the partner system comes after the Web Request is completed). With this scheme our serialized State Machine can not receive this event and when it is restored from the new Web Request arrives, restored State Machine will know nothing about this event.
Fortunately there is a possibility in Spring Web Flow to configure this behaviour, so instead of it serialize our State Machine it will keep it in memory.
The setting looks like following.
<flow:flow-executor id="flowExecutor"> <flow:flow-execution-listeners> <flow:listener ref="facesContextListener" /> </flow:flow-execution-listeners> <strong><flow:flow-execution-repository max-execution-snapshots="0" /></strong> </flow:flow-executor>
snippet 47
In webflow-config.xml at the project techdemo project.
If the ‘max-execution-snapshots’ property is set to 0, Spring Web Flow will no more serialize the objects but keeps them in memory so the when web request ended if our State Machine receives it can still process them.
The end effect would look like following,
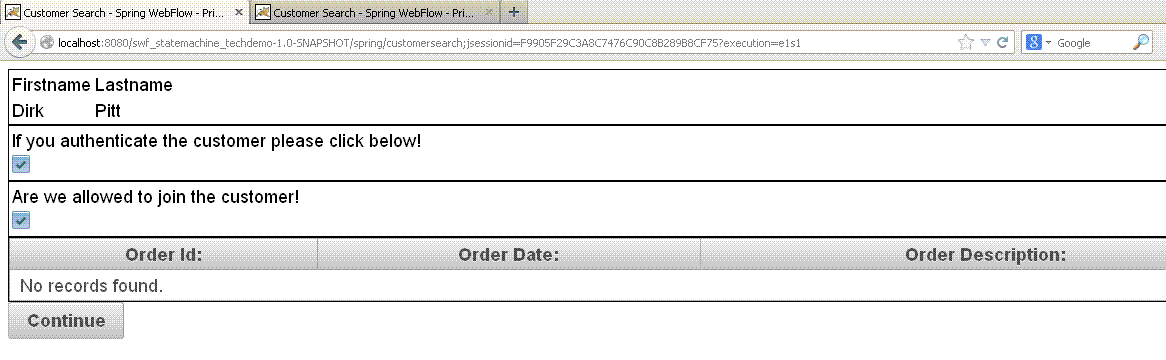
picture 29
at the above picture you see the aplicationg with flowId e1s1 in a certain state and in the following picture with flowId e1s2.

picture 30
as you browser view 2 tabs has no negative effect on the functionality of the browser.
Primefaces and Spring
Integration of Primefaces and Spring surprisingly extremely easy, we have to make some configurations in web.xml.
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/j2ee/web-app_3.0.xsd">
.......
<!-- /WEB-INF/config/applicationContext.xml -->
<servlet>
<servlet-name>spring_mvc</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet
</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>/WEB-INF/config/webmvc-config.xml,
/WEB-INF/config/webflow-config.xml,
/WEB-INF/config/applicationContext-customersearch.xml,
classpath:/META-INF/customersearch/applicationContext-statemachine-customersearch.xml,
classpath:/META-INF/customersearch/applicationContext-statemachine-customersearch-guards.xml,
classpath:/META-INF/customersearch/applicationContext-statemachine-customersearch-controlobjects.xml,
classpath:/META-INF/findcustomer/applicationContext-statemachine-findcustomer.xml,
classpath:/META-INF/findcustomer/applicationContext-statemachine-findcustomer-guards.xml,
classpath:/META-INF/findcustomer/applicationContext-statemachine-findcustomer-controlobjects.xml,
classpath:/META-INF/findorders/applicationContext-statemachine-findorders.xml,
classpath:/META-INF/findorders/applicationContext-statemachine-findorders-guards.xml,
classpath:/META-INF/findorders/applicationContext-statemachine-findorders-controlobjects.xml
/WEB-INF/config/applicationContext-manager.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet>
<servlet-name>SpringResourceServlet</servlet-name>
<servlet-class>org.springframework.js.resource.ResourceServlet</servlet-class>
<load-on-startup>0</load-on-startup>
</servlet>
<servlet>
<servlet-name>PrimefacesResourceServlet</servlet-name>
<servlet-class>org.primefaces.resource.ResourceServlet</servlet-class>
</servlet>
<servlet>
<servlet-name>FacesServlet</servlet-name>
<servlet-class>javax.faces.webapp.FacesServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
.....
<servlet-mapping>
<servlet-name>PrimefacesResourceServlet</servlet-name>
<url-pattern>/primefaces_resource/*</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>SpringResourceServlet</servlet-name>
<url-pattern>/resources/*</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>spring_mvc</servlet-name>
<url-pattern>/spring/*</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>FacesServlet</servlet-name>
<url-pattern>/faces/*</url-pattern>
</servlet-mapping>
</web-app>
snippet 47a
It is actually consists of defining the Spring DispatcherServlet which is responsable for initializing the Spring Framework and the states application context files like ‘/WEB-INF/config/webmvc-config.xml, /WEB-INF/config/webflow-config.xml, /WEB-INF/config/applicationContext-customersearch.xml’ and of course FacesServlet.
The rest is only defining Primefaces dependencies in the Maven pom file.
<dependencies>
.........
<!-- PRIMEFACES -->
<dependency>
<groupId>org.primefaces</groupId>
<artifactId>primefaces</artifactId>
</dependency>
........
</dependencies>
snippet 47b
And of course using primefaces tags in the .xhtml files.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:fn="http://java.sun.com/jsp/jstl/functions"
xmlns:p="http://primefaces.prime.com.tr/ui">
<f:view contentType="text/html" encoding="UTF-8">
<h:head>
<title>Customer Search - Spring WebFlow - Primefaces - State Machine Demo</title>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type" />
</h:head>
<body>
<script>
function handlePublish(pushed) {
handlePublishInternal();
}
</script>
<p:outputPanel ajaxRendered="true" id="handlePuplishRemoteCommand">
........
</p:outputPanel>
.......
<p:commandButton id="customerSearchViewCustomerDetail" value="Continue"
ajax="true" update="customerSearchRunning-panel_empty_layout,customerSearchFound-empty-panel,customerSearchAuthentication-empty-panel">
</p:commandButton>
</h:form>
</body>
</f:view>
</html>
snippet 47c
One point that you have to pay attention here, Primefaces needs some Javascripts to operate, to be include those sucessfully to the rendered page, folowing tag should be included to the root .xhtml file.
<h:head> ....... </h:head>
snippet 47d
After that you can use Spring and Primefaces together.
You can even bring this one step further if you define the following element in your faces-config.xml, that mean you can reference your Spring beans directly from .xhtml files.
<?xml version="1.0" encoding="UTF-8"?>
<faces-config xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-facesconfig_2_1.xsd"
version="2.1">
<application>
<el-resolver>
org.springframework.web.jsf.el.SpringBeanFacesELResolver
</el-resolver>
</application>
</faces-config>
snippet 47f
-Comet/Atmosphere
If you follow our discussion until now, one really critical future our application is able notify asynchronously the web browser that there is a State change in our State Machine and it should re-render.
The general concept of forcing a browser to re-render that is called Comet technologies which can be summarized keeping a channel open Web Servers to get asynchronous notifications.
Typical implementation of this new technology is Jetty Continuation, Tomcat CometProcessor, Grizzly CometHandler or Netty WebSocket but as you they are tightly coupled with the platform mentioned or Open Source Frameworks like Atmosphere, cometD or JWebSocket.
For our application we choose the use Primefaces for JSF implementation and their way of dealing with Comet is Atmosphere so we will analyze this.
Atmosphere is based Web Socket technology and all major containers like Jetty, Tomcat, Grizzly, Netty are Web Socket compatible.
All the magic of Atmosphere happens inside of the AtmosphereServlet which we should configure in our web.xml (we are using Primefaces so we are using a sub class of it ‘PushServlet’ from Primefaces).
Dependent of your application server is WebSocket compatible or not, Atmosphere has two ways of dealing with the problem. If it is WebSocket compatible it will use Native IO and open a non blocking communication which means the channel with the web browser and server will stay open but it will not block any of the application server’s threads and if it is not WebSocket compatible it will block one of the application server threads. You should consider this when you are doing you capacity planning.
When client connects to the atmosphere, it will open a communication channel and subscribe there topics that push components in the browser listen and when an interesting event for this topic happens a broadcaster will publish this.
So lifecycle happens as following, client send a request which will suspend until an interesting event occurs for the GUI, broadcaster will publish this and when this connection is not necessary anymore it would be shutdown.
-Creation of Custom Steorotypes
We are using UML language but there are some cases that information that we can represent in our Model is not enough to our implementation.
This is the case for us for ex, when we are try to store the information about what the name of the actual implementation class for our transition actions and guards.
If you remember the following pictures

picture 31
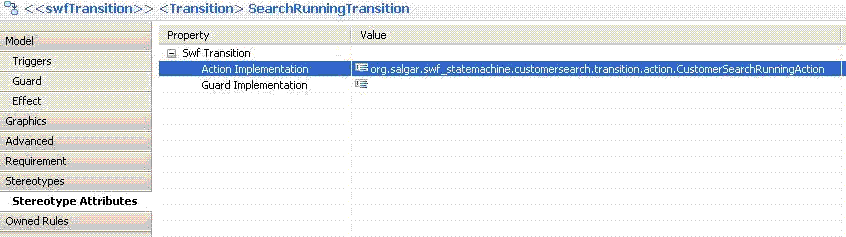
picture 32
We used here a new element to store the information we need. This is a standard UML concept called Stereotypes which is exactly designed for our purpose.
As you see I created a stereotype called swf_statemachine::SwfTransition, which a stereotype that can be decorated on Transition (which in the screenshot I decorated on the SearchRunningTransition) and contains 2 attributes called Action Implementation and Guard Implementation.
So how can you create stereotypes and introduces them to the UML Model. I will explain the process for Topcased.
First of we have to create a new model in Topcased with the following settings.

picture 33
The keyword here, we selected a profile element as a template and swf_test as profile name.
In the next step, we created our Stereotype, StatemachineTestStereotype

picture 34
based on MetaClass StateMachine, which means the moment we defined the MetaClass this Stereotype can only be applied to this type objects, in this case uml::statemachine object.
Now we can use these Stereotypes to transfer more information to the UML Model or we can just use to tag the object that we want to have a special behaviour. For ex, M2T when it sees this Steorotype, it applies a special template to the tagged element.
Now let’s see how we can define properties to a Stereotype which can have simple types like strings or complex types like enumerations.

picture 35
Now our Stereotype is complete but how we will introduce it to our model. First we have to define our Stereotype UML way which can be done with the following command.

picture 36
Now save and your new Stereotype is ready to use only thing you have to do include into the model.
picture 37
Load your new Stereotype/Profile as resource to the model you want to use and also choose apply profile after it (One thing to point out here, when you would try to load the Resource it will present the option to use the absolute path or the relative to your workspace, use relative option otherwise you might get problems with portability from environment to environment).
picture 38
Which will present you the menu and we should select StateMachineTest (in this case I am selecting SwfStateMachine profile I actually use in the model).

picture 39
Groovy – Runtime Modification of the State Machine on Production
One thing that might be criticized for the ideas cited above is that you have to know all of your use cases before going to the production. This means that a system that is not using the above ideas if it encounters an use cases that it doesn’t know how to handle, it might somehow work.
It might do the correct thing or not but it will continue to work, off course it will not report you that something occurred that it does not know how to handle, so you can take the precaution next time but it will not block the user.
With a State Machine the situation is contrary if State Machine encounters an Use Case that it does not know, it will stop the world and the user will not able to proceed, off course it will report the use case so you can resolve it for the next software delivery.
This can be quite problematic especially at the start-up of an application, which will contain lots of unknowns and bugs which will be fixed in future iterations but that will not help the user first discovering this problems.
To deliver a solution to the user who doesn’t want to wait for next 3 months for the solution we should have a mechanism. This mechanism what I call is dynamic configuration of a State Machine during runtime.
As you read in the previous sections, all the information influencing what will be displayed our web application GUI is held the Control Objects of our State Machines so if you can modify these data on the runtime; we can change the behaviour of our application on the runtime.
So how are we going to do this?
We will encounter most of the missing Use Cases when we are at certain State in our State Machine and user triggers an event that we were not expecting because either we didn’t know the Use Case or it is just a bug.
Off course, this idea should not be abused, this is a solution to solve critical production software problems; it should not be used as a standard software development method. Dynamically defined State Machine definitions after the emergency solution had implemented, it has to be transferred to UML diagrams for the next release.
So what will happen is that in our application we will have a database table which contains the information telling us, for which State Machine, Event, Transition and Guard condition dynamic configuration should occur and which Action should this dynamic configuration should execute.
The critical point here is the definition of the Guard Condition and Activity, these will be saved as Groovy Scripts in the database so you can place those in a running Production system so it can change the behaviour of the Control Objects of the State Machine.
To reach this goal, we will have special Action Type called GroovyAction which will be used for the Transition that we configured in the database.
public class GroovyAction implements IAction {
private String groovyScript;
public void processAction(TvppEvent tvppEvent, IStateMachineContext stateMachineContext,
IStateMachine stateMachine) {
Map<String, Object> binderContainer = new HashMap<String, Object>();
binderContainer.put("stateMachineContext", stateMachineContext);
Binding binding = new Binding();
binding.setVariable("bindingContainer", binderContainer);
GroovyShell groovyShell = new GroovyShell(binding);
groovyShell.evaluate(groovyScript);
}
public void setGroovyScript(String groovyScript) {
this.groovyScript = groovyScript;
}
}
snippet 48
As you see, this binds the State Machine configured for this Transition to a binding container for Groovy so groovy script can access it. The Groovy Script configured in the database will be injected to this Action so we can call ‘groovyShell.evaluate(groovyScript)’ method so we can execute the Groovy code, which would look like the following.
def stateMachineContext = (StateMachineContext) bindingContainer['stateMachineContext']
def myTest = (CustomersearchSMControlledObject) stateMachineContext.controlObjects['customersearchSMControlledObject']
myTest.setRenderSearchEnabled = false;
snippet 49
which obtains the reference to the Control Object and set the value for the variable controlling the visibility of the Search button and set that to ‘false’ so it will not be rendered anymore.
One thing to consider here, what we offer with this feature is just emergency case solutions, if your application in production would not work because of an use case you didn’t discovered during development and test phase, this will enable you quickly solve the problem. This should not be used as regular development method because this will take us away from the Model Driven Software Development principles.
After the emergency is resolved, discovered Use Cases must be transferred to the UML Model and emergency solution should be removed from the database with the next deployment to the production.
Preparing Project Environment
I think we reached to the point where you want to get your hands dirty.
The project controlled with a version control system called git, which you can download from following URL (http://git-scm.com/).
Personally I am using cygwin (a windows unix shell emulator) and its git client but you can also download a graphical user interface like TortoiseGit (http://code.google.com/p/tortoisegit/).
If you use cygwin or any git shell version you can get the project with the following command:
git clone -b MWE2 git@github.com:mehmetsalgar/swf_statemachine.git
This will load from the github, the project files and create the directory structure that I showed in the previous screenshots.
A successful git clone will look like the following.
git clone -b spring4_update git@github.com:mehmetsalgar/swf_statemachine.git
Cloning into ‘swf_statemachine’…
remote: Reusing existing pack: 926, done.
remote: Counting objects: 35, done.
remote: Compressing objects: 100% (29/29), done.
remote: Total 961 (delta 7), reused 0 (delta 0)
Receiving objects: 100% (961/961), 205.38 KiB | 309 KiB/s, done.
Resolving deltas: 100% (270/270), done.
If you see the following message that means you are successfully got the project to your environment.
The project is a Maven project so if you don’t have a Maven in your environment, you have to download it from (http://maven.apache.org/download.cgi).
If you are not an experienced with Maven, one point you have to be careful if you are working behind company firewall, you have to configure the following lines in setting.xml in conf directory of your Maven installation.
<proxies>
<!-- proxy
| Specification for one proxy, to be used in connecting to the network.
| -->
<proxy>
<id>optional</id>
<active>true</active>
<protocol>http</protocol>
<username>xxxxx</username>
<password>xxxxxx</password>
<host>some.proxy.com</host>
<port>3128</port>
<nonProxyHosts>127.0.0.1</nonProxyHosts>
</proxy>
</proxies>
snippet 50
If you are working with windows, it might be wise to change your maven repository location from your MyDocuments to a simpler path because some classpaths becomes too deep and have problems with 255 character limit of windows. So it is better to select a shallow directory position for your repository, for ex . c:/repo_mvn3.
<localRepository>c:/repo_mvn</localRepository>
snippet 51
Now you can build the project for the first, execute the following command in DOS prompt or in cygwin ‘
/swf_statemachine/swf_statemachine’
mvn clean install
If you see the following message that means your build was successful.
[INFO] ————————————————————————
[INFO] Reactor Summary:
[INFO]
[INFO] Spring WebFlow – State Machine ……………….. SUCCESS [3.422s]
[INFO] Spring WebFlow – State Machine – Comet ………… SUCCESS [37.095s]
[INFO] Spring WebFlow – State Machine – Fornax Extensions SUCCESS [10.609s]
[INFO] Spring WebFlow – State Machine – Domain Model ….. SUCCESS [16.313s]
[INFO] Spring WebFlow – State Machine – XPand(M2T) Templates SUCCESS [0.812s]
[INFO] Spring WebFlow – State Machine – Implementation … SUCCESS [2.766s]
[INFO] Spring WebFlow – State Machine – Techdemo Domain Model SUCCESS [7.844s]
[INFO] Spring WebFlow – State Machine – Statemachine Model SUCCESS [6:34.974s]
[INFO] Spring WebFlow – State Machine – Statemachine Model Implementation SUCCESS [3.093s]
[INFO] Spring WebFlow – State Machine – TechDemo ……… SUCCESS [22.751s]
[INFO] ————————————————————————
[INFO] BUILD SUCCESS
[INFO] ————————————————————————
[INFO] Total time: 8:20.303s
[INFO] Finished at: Fri Mar 21 10:18:23 CET 2014
[INFO] Final Memory: 76M/495M
[INFO] ————————————————————————
As I mentioned before I used TOPCASED for modeling purposes (you can download it from here)(Correction: It seems another company overtook the project but you can download the binaries from here: TOPCASED 5.3.1) on this project. TOPCASED is also a Java Development Environment.
If you decide to work with Eclipse environment, you have two options to bring the projects under the Eclipse. All modern Eclipse releases will include automatically M2Eclipse plugin so you can just Import your project as a Maven Project.

picture 40
Or if you don’t want to use M2Eclipse, you can use following command
mvn eclipse:eclipse
and import created projects as Eclipse Projects.

picture 41
Personally I developed the techdemo application in a Tomcat but there is nothing preventing that it would be deployed to JBoss, Glassfish, Jetty and other containers.
For Tomcat there is one critical modification in the container to bring Techdemo running. Techdemo application uses extensively Primefaces and Atmosphere/Comet framework for Ajax pull functionality. Tomcat a special configuration to activate the Websocket, which is a crucial part of the Atmosphere framework.
The following changes has to be made in server.xml of the Tomcat
<Connector port="8080" protocol="org.apache.coyote.http11.Http11NioProtocol"
connectionTimeout="20000"
redirectPort="8443 />
snippet 52
org.apache.coyote.http11.Http11NioProtocol is the protocol which is supporting the Websocket protocol.
After you that when you copy swf_statemachine_techdemo-1.0-SNAPSHOT.war to webapps directory of the tomcat and fire up the tomcat with startup.bat and you are ready to go.
To reach the techdemo application you have to call the following url (http://localhost:8080/swf_statemachine_techdemo-1.0-SNAPSHOT/spring/customersearch).
Test Rig
One of the biggest advantages of the methodic we explaing until here is the testablity. With the information you have until now you can test your whole GUI with unit tests. Lets see how can we do that.
We can actually test which GUI elements will be displayed in the GUI in a test rig.
Unit test constructed as following with the test org.salgar.swf_statemachine.customersearch.CustomerSearchStateMachineTest.
First of all we have to initialize all the Spring Application Context which consists from following elements…
@ContextConfiguration(locations = {
"/META-INF/scope.xml",
"/META-INF/customersearch/applicationContext-statemachine-customersearch.xml",
"/META-INF/customersearch/applicationContext-statemachine-customersearch-guards.xml",
"/META-INF/customersearch/applicationContext-statemachine-customersearch-controlobjects.xml",
"/META-INF/findcustomer/applicationContext-statemachine-findcustomer.xml",
"/META-INF/findcustomer/applicationContext-statemachine-findcustomer-guards.xml",
"/META-INF/findcustomer/applicationContext-statemachine-findcustomer-controlobjects.xml",
"/META-INF/findorders/applicationContext-statemachine-findorders.xml",
"/META-INF/findorders/applicationContext-statemachine-findorders-guards.xml",
"/META-INF/findorders/applicationContext-statemachine-findorders-controlobjects.xml",
"/META-INF/applicationContext-customerManager-mock.xml" })
public class CustomerSearchStateMachineTest extends
AbstractTestNGSpringContextTests {
snippet 53
which are in this case StateMachine definitions of the Customer Search SM, Find Customer SM, Find Orders SM and their control objects and guards.
First we have to mock our Comet System (which is responsible for our asynchronous communication with the web browser, I will explain the principles in the Appendix).
@Test(dependsOnMethods = { "initialisation" })
public void startSearch() {
CometServiceLocatorMocker.mock();
Broadcaster broadCasterMock = CometServiceLocatorMocker.getMockObject();
snippet 54
After that we will initialize our test for this StateMachine.
StateMachine customerSearchSM = (StateMachine)this.applicationContext.getBean("CustomerSearchSM");
customerSearchSM.resetStateMachine();
Assert.assertNotNull(customerSearchSM);
Assert.assertEquals(StateMachineEnumerationImpl.CustomerSearchSM
.getStateMachineName(), customerSearchSM.giveActualState()
.getName().getStateMachineName().getStateMachineName());
snippet 55
Initial State of our GUI, nothing should be rendered in the GUI other then CustomerSearchInput (which can be seen in the screen shot above for the State WAITING_FOR_CUSTOMERSEARCH_START)
)
Assert.assertEquals( CustomerSearchSM_StateEnumerationImpl.WAITING_CUSTOMERSEARCH_START,
customerSearchSM.giveActualState().getName());
Assert.assertEquals(Boolean.TRUE,
((CustomerSearchInputCO) customerSearchSM.getControlObject())
.getRenderCustomerSearchInput());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchRunningCO) customerSearchSM.getControlObject())
.getRenderCustomerSearchRunning());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchAuthenticationCO) customerSearchSM.getControlObject())
.getRenderCustomerSearchAuthentication());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchFoundCO) customerSearchSM.getControlObject())
.getRenderCustomerSearchFound());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchJoinCO) customerSearchSM.getControlObject())
.getRenderCustomerJoin());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchOrderCO) customerSearchSM.getControlObject())
.getRenderCustomerOrders());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchOrderCO) customerSearchSM.getControlObject())
.getRenderCustomerOrderLoading());
snippet 56
As you might see I can check in Test Rig how exactly GUI should display when my real use case executed. It checks that in this state only INPUT form displayed and nothing else.
As following step we are triggering the event simulating the user click to search start button.
CustomerSearchStartEventPayload customerSearchStartEventPayload = new CustomerSearchStartEventPayload(); Event onSearchStartEvent = new Event(); onSearchStartEvent .setEventType(CustomerSearchSM_EventEnumerationImpl.onStartSearch); customerSearchStartEventPayload.setCustomerNumber(customerNumber); onSearchStartEvent.setPayload(customerSearchStartEventPayload);
snippet 57
Following steps are initializing some Mock Objects that are simulating Partner System, this is not interesting technology for our test rig so I will not display the details here.
Event looks like as following…
CustomerSearchStartEventPayload customerSearchStartEventPayload = new CustomerSearchStartEventPayload(); Event onSearchStartEvent = new Event(); onSearchStartEvent .setEventType(CustomerSearchSM_EventEnumerationImpl.onStartSearch); customerSearchStartEventPayload.setCustomerNumber(customerNumber); onSearchStartEvent.setPayload(customerSearchStartEventPayload); customerSearchSM.handleEvent(onSearchStartEvent);
snippet 58
After State Machine make the necessary changes and we check again the results. GUI will be in State CUSTOMERSEARCH_RUNNING and GUI elements that should be displayed is visible in above Screenshot.
Assert.assertEquals( CustomerSearchSM_StateEnumerationImpl.CUSTOMERSEARCH_RUNNING, customerSearchSM.giveActualState().getName()); Assert.assertEquals(customerNumber, ((CustomerSearchCO) customerSearchSM.getControlObject()) .getCustomerNumber()); Assert.assertEquals(Boolean.FALSE, ((CustomerSearchInputCO) customerSearchSM.getControlObject()) .getRenderCustomerSearchInput()); Assert.assertEquals(Boolean.TRUE, ((CustomerSearchRunningCO) customerSearchSM.getControlObject()) .getRenderCustomerSearchRunning()); Assert.assertEquals(Boolean.FALSE, ((CustomerSearchAuthenticationCO) customerSearchSM.getControlObject()) .getRenderCustomerSearchAuthentication()); Assert.assertEquals(Boolean.FALSE, ((CustomerSearchFoundCO) customerSearchSM.getControlObject()) .getRenderCustomerSearchFound()); Assert.assertEquals(Boolean.FALSE, ((CustomerSearchJoinCO) customerSearchSM.getControlObject()) .getRenderCustomerJoin()); Assert.assertEquals(Boolean.FALSE, ((CustomerSearchOrderCO) customerSearchSM.getControlObject()) .getRenderCustomerOrders()); Assert.assertEquals(Boolean.FALSE, ((CustomerSearchOrderCO) customerSearchSM.getControlObject()) .getRenderCustomerOrderLoading());
snippet 59
You may see from here that we are checking the State Machine change to the correct state and all the correct GUI elements are displayed or not? In this case Search Input form should be invisible and the GUI must inform the user the search is ongoing and all other GUI elements must be invisible.
We can again perfectly control in our test rig that application is working correctly.
After this we will prepare some more Mock Services simulating partner Systems and finally send our State Machine the event signalising the customer is found.
Event customerFoundEvent = new Event(); customerFoundEvent.setPayload(customer); customerFoundEvent.setSource(this); customerFoundEvent.setEventType(FindCustomerSM_EventEnumerationImpl.onCustomerFound); ((CustomerSearchSMControlObject) customerSearchSM.getControlObject()) .getFindCustomerSlaveSM().handleEvent(customerFoundEvent);
snippet 60
Finally when we reach the state CUSTOMER_FOUND following elements would be controlled (can be seen in the screenshot).
Assert.assertEquals(CustomerSearchSM_StateEnumerationImpl.CUSTOMER_FOUND,
customerSearchSM.giveActualState().getName());
Assert.assertEquals(CustomerSearchSM_StateEnumerationImpl.CUSTOMERSEARCH_RUNNING,
customerSearchSM.giveActualState().getName());
Assert.assertEquals(customerNumber,
((CustomerSearchCO) customerSearchSM.getControlObject()).getCustomerNumber());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchInputCO) customerSearchSM.getControlObject()).getRenderCustomerSearchInput());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchRunningCO)customerSearchSM.getControlObject()).getRenderCustomerSearchrunning());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchAuthenticationCO) customerSearchSM.getControlObject())
.getRenderCustomerSearchAuthentication());
Assert.assertEquals(Boolean.TRUE,
((CustomerSearchFoundCO) customerSearchSM.getControlObject())
.getRenderCustomerSearchFound());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchJoinCO) customerSearchSM.getControlObject()).getRenderCustomerJoin());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchOrderCO) customerSearchSM.getControlObject()).
getRenderCustomerOrders());
Assert.assertEquals(Boolean.FALSE,
((CustomerSearchOrderCO) customerSearchSM.getControlObject())
.getRenderCustomerOrderLoading());
snippet 61
M2T
M2T Xpand is a template language to generate Text Output from Meta Models based on EMF. It is possible to use this with many different DSL languages like UML if the correct Meta Model is defined.
For Xpand to convert Model to Text, it needs a Workflow to define how/where to load models, checking them and generating Text.
If we look to the worklow we used in swf_statemachine_sm_model/src/main/resources/workflow.mwe here are the Elements we used.
<bean class="org.salgar.swf_statemachine.uml2.Setup" standardUML2Setup="true" />
snippet 62
which initialiaze the Namespaces for the UML for XPand.
The following Snippet defines for this Workflow the Meta Model that XPand muss interpret UML is.
<bean id="uml" class="org.eclipse.xtend.typesystem.uml2.UML2MetaModel"/>
snippet 63
This will make all standard UML Element known to Xpand but if you remember previous topics there is one concept called Steoropes which allow us to store information that is normally not possible via UML.
We should also make this Meta Model known to Xpand if these Steorotypes would be interpreted via Xpand.
<bean id="swf_statemachine" class="org.eclipse.xtend.typesystem.uml2.profile.ProfileMetaModel"> <profile value="platform:/resource/swf_statemachine_sm_model/src/main/resources/swf_statemachine.profile.uml"/> </bean>
snippet 64
Now with this information a XPand generator can interpret the information we contain in an UML Model and generate Text from it.
Following is a definition of such a generator.
<component id="springGenerator" class="org.eclipse.xpand2.Generator" skipOnErrors="true"> <fileEncoding value="ISO-8859-1" /> <!--metaModel idRef="EmfMM" /--> <metaModel idRef="uml" /> <metaModel idRef="swf_statemachine" /> <expand value="template::stateMachineSpring::Spring FOR model" /> <outlet path="src/generated/resources" > <postprocessor class="org.salgar.m2t.xml.XmlBeautifier" /> </outlet> </component>
snippet 65
As you see we introduce to the generator previously defined Meta Models, uml and swf_statemachine then we instruct generator to expand ‘template::stateMachineSpring::Spring FOR model’.
Now if you look to the ‘swf_statemachine_xpand’ project there is a ‘template’ directory containing ‘stateMachineSpring.xpt’ template file. With the expression ‘template::stateMachineSpring::Spring FOR model’ Xpand was able to locate this file in the classpath.
If you open and observe this file you will see that
«DEFINE Spring FOR uml::Model» «EXPAND Root(this) FOREACH (List[uml::Package])ownedElement» «EXPAND SteorotypeGuardsActions(this) FOREACH (List[uml::Package])ownedElement» «EXPAND ControlObjects(this) FOREACH (List[uml::Package])ownedElement» «ENDDEFINE»
snippet 66
it contains a definition for ‘Spring FOR uml::Model’ which means that UML Model that this workflow will transfer to this template file would be called ‘Spring’ and with the statement
«EXPAND Root(this) FOREACH (List[uml::Package])ownedElement»
snippet 67
it should call the ‘Root’ function for the every ‘uml::Package’ inside of the ‘uml::model’.
This is the general principle how XPand works. We define structures which tells Xpand how the handle specific elements in the model.
For ex.
«DEFINE Root(uml::Model model) FOR uml::Package» «IF ownedType.typeSelect(uml::StateMachine).isEmpty==false» «FILE "META-INF/" + name + "/applicationContext-statemachine-"+name+".xml"» <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:util="http://www.springframework.org/schema/util" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd"> «EXPAND StateMachines(model) FOREACH ownedType.typeSelect(uml::StateMachine)» <bean name="defaultGuard" class="org.salgar.swf_statemachine.impl.guard.DefaultGuardImpl" /> <bean name="defaultAction" class="org.salgar.swf_statemachine.impl.action.DefaultAction" /> </beans> «EXPAND Root(model) FOREACH nestedPackage» «ENDFILE» «ELSE» «EXPAND Root(model) FOREACH nestedPackage» «ENDIF» «ENDDEFINE»
snippet 68
tells Xpand create a Spring configuration while for every State Machine in the model that doesn’t containing a Sub State Machine and expand those State Machines
«EXPAND StateMachines(model) FOREACH ownedType.typeSelect(uml::StateMachine)»
snippet 69
and expand those also for every nested UML Package that these package contains.
«EXPAND Root(model) FOREACH nestedPackage»
snippet 70
This is the working principle of Xpand, we define structure to tell XPand how to handle certain type and let the Xpand loop over them.
